
Привет! Это вторая часть из цикла статей "Ультимативный гайд по структурам данных и алгоритмам на Python" 🧠. В первой части мы заложили фундамент, разобравшись с базовыми инструментами, которые Python предоставляет "из коробки". Мы увидели их сильные стороны и "подводные камни" производительности. Теперь пора двигаться дальше и осваивать более продвинутые концепции и инструменты!
Весь маршрут нашего гайда:
Сегодня мы фокусируемся на двух важных темах, которые помогут нам эффективнее работать с последовательностями и подготовят к более сложным структурам:
Эти две темы — отличный пример того, как разные подходы к организации данных в памяти влияют на производительность и возможности.
- `collections.deque`. Познакомимся с быстрым родственником `list`, который создан для эффективной работы с обоими концами последовательности.
- Связанные списки (Linked Lists). Нырнем в классику Computer Science. Узлы, ссылки, обходы... Разберемся, как они устроены, почему эта концепция важна для понимания других структур (вроде деревьев) и почему о них всё еще спрашивают на собеседованиях 😉.
Эти две темы — отличный пример того, как разные подходы к организации данных в памяти влияют на производительность и возможности.
Эффективные стеки и очереди
В мире алгоритмов мы часто сталкиваемся с необходимостью обрабатывать элементы в определенном порядке. Две очень распространенные абстрактные структуры данных — это стек (stack) и очередь (queue). Как раз они и определяют, в каком порядке мы можем добавлять и извлекать элементы. Без них не обходится множество алгоритмов: от разбора выражений и обхода графов до управления задачами в многопоточных приложениях.
- Стек: последним пришел — первым вышел (LIFO - Last-In, First-Out). Представьте стопку тарелок: вы кладете очередную тарелку сверху и берете для еды (или мытья) тоже сверху. Последний добавленный элемент будет взят первым. Основные операции: `push` (положить сверху) и `pop` (взять сверху).
- Очередь: первым пришел — первым ушел (FIFO - First-In, First-Out). Тут все как в очереди к кассе или на аттракцион. Кто пришел первым, тот первым и пройдет. Новые элементы добавляются в конец очереди (`enqueue`), а обслуживаются (извлекаются) те, кто стоит в начале (`dequeue`).
"А что, списки не подходит?" 🤔
Казалось бы, у нас уже есть универсальный список, может, он справится?
- Для стека (LIFO): Вполне! Операция `list.append(item)` отлично работает как `push` (добавление в конец/наверх), а `list.pop()` (без индекса!) — как `pop` (удаление с конца/сверху). Обе эти операции для списков очень быстрые — O(1) (амортизированное для `append`). Так что для реализации простого стека `list` часто подходит идеально.
- Для очереди (FIFO): А вот тут засада! 😬 Добавить в конец (`enqueue`) с помощью `list.append(item)` мы можем так же быстро (O(1)). Но как извлечь элемент из начала (dequeue)? Нам придется использовать `list.pop(0)`. И тут мы наступаем на старые грабли: `pop(0)` — это медленная операция O(n), так как всем элементам оставшегося списка нужно сдвинуться в памяти на одну позицию влево. На больших очередях такие постоянные сдвиги превращаются в серьезное бутылочное горлышко.
Почему O(n)? Потому что, как мы помним из Части 1, список в Python — это динамический массив. Когда вы удаляете нулевой элемент, все остальные элементы (а их может быть n-1) должны физически сдвинуться в памяти на одну позицию влево, чтобы заполнить образовавшуюся пустоту. Представьте, что в живой очереди уходит первый человек, а вся остальная толпа должна сделать шаг вперед. Если очередь длинная, это занимает время.
Давайте посмотрим на это безобразие в миниатюре:
# Анти-пример: Очередь на list
print("Демонстрация проблемы с list.pop(0):")
queue_list = ['A', 'B', 'C', 'D']
print(f" Исходная очередь: {queue_list}, id: {id(queue_list)}")
# Извлекаем первый элемент (Dequeue) - O(n)!
first_item = queue_list.pop(0)
print(f" Извлекли: '{first_item}'")
print(f" Очередь после pop(0): {queue_list}, id: {id(queue_list)}")
# Заметьте, что 'B', 'C', 'D' сдвинулись на индексы 0, 1, 2!
# ID списка тот же, но внутреннее содержимое перестроено.На четырех элементах это незаметно. Но представьте очередь из тысяч или миллионов сообщений, задач или запросов. Постоянные сдвиги всего массива при каждом извлечении элемента превратят вашу программу в улитку 🐌
К счастью, Python предлагает элегантное и эффективное решение этой проблемы 👇🏻
deque: решение проблемы ✨
К счастью, разработчики Python позаботились о нас и включили в стандартную библиотеку (collections) специальный класс, идеально подходящий для эффективной работы с обоими концами последовательности — `collections.deque`.
Произносится как "дек", что является сокращением от double-ended queue (двусторонняя или двусвязная очередь). И это название отлично отражает его суть!
В чем секрет скорости deque?
В отличие от списков, которые внутри устроен как непрерывный блок памяти, `deque` реализован хитрее — как двусвязный список блоков памяти (doubly-linked list of fixed-size blocks).
Представьте себе не одну длинную полку (как список), а несколько коротких полок (блоков), соединенных цепями с обеих сторон (двусвязный список). Добавить или убрать предмет с самого начала или самого конца такой конструкции очень легко — нужно поработать только с крайним блоком и его связями. Не нужно двигать все предметы на всех полках!
Именно эта структура позволяет `deque` выполнять операции добавления и удаления элементов с обоих концов за гарантированное константное время O(1). Никаких массовых сдвигов элементов, как в `list.pop(0)` или `list.insert(0, ...)`.
Вот четыре основных метода, которые делают deque таким мощным для стеков и очередей:
- `d.append(x)`: Добавить x в правый конец (как `list.append`). Сложность: O(1).
- `d.pop()`: Удалить и вернуть элемент из правого конца (как `list.pop()`). Сложность: O(1).
- `d.appendleft(x)`: Добавить `x` в левый конец. Сложность: O(1).
- `d.popleft()`: Удалить и вернуть элемент из левого конца. Сложность: O(1).
from collections import deque
# Создаем deque
d = deque(['b', 'c', 'd'])
print(f"Исходный deque: {d}")
# Работаем с правым концом (как list)
d.append('e') # O(1)
print(f"После append('e'): {d}")
item_right = d.pop() # O(1)
print(f"После pop(): {item_right=}, deque: {d}")
# Работаем с левым концом (быстро, в отличие от list!)
d.appendleft('a') # O(1)
print(f"После appendleft('a'): {d}")
item_left = d.popleft() # O(1)
print(f"После popleft(): {item_left=}, deque: {d}")А что с доступом по индексу?
deque поддерживает доступ к элементам по индексу (d[i]) и срезы, как и списки. Однако, из-за его "блочной" структуры, доступ по индексу в deque — это операция O(n) в худшем случае (особенно для элементов в середине). Хотя для элементов, близких к краям, доступ может быть быстрым (ближе к O(1)), в общем случае для произвольного доступа по индексу list (с его O(1)) будет эффективнее.
Вывод: `deque` — это не полная замена списков. Это специализированный инструмент, который очень хорош, когда вам нужны быстрые (O(1)) операции добавления/удаления с обоих концов последовательности.
Теперь давайте посмотрим, как это великолепие применяется на практике для стеков и очередей!
Пример использования deque для стеков (LIFO)
Представим простую систему отмены действий (`Undo`). Каждое выполненное действие мы будем добавлять в стек. Если пользователь нажимает "Отмена", мы просто извлекаем последнее действие из стека.
from collections import deque
# Используем deque как стек для истории команд
command_history = deque()
print("Симуляция работы с текстовым редактором:")
# Пользователь выполняет действия (push через append)
action1 = "Набрать текст: 'Привет'"
command_history.append(action1)
print(f" -> Выполнено: '{action1}', Стек: {command_history}")
action2 = "Сделать текст жирным"
command_history.append(action2)
print(f" -> Выполнено: '{action2}', Стек: {command_history}")
action3 = "Добавить смайлик 😎"
command_history.append(action3)
print(f" -> Выполнено: '{action3}', Стек: {command_history}")
# Пользователь нажимает "Отмена" (pop)
print("\nНажата кнопка 'Отмена'...")
if command_history: # Проверяем, что стек не пуст
last_action = command_history.pop() # O(1)
print(f" <- Отменено действие: '{last_action}'")
print(f" Осталось в стеке: {command_history}")
else:
print("Нет действий для отмены.")
# Еще раз "Отмена"
print("\nНажата кнопка 'Отмена'...")
if command_history:
last_action = command_history.pop() # O(1)
print(f" <- Отменено действие: '{last_action}'")
print(f" Осталось в стеке: {command_history}")
else:
print("Нет действий для отмены.")Как видим, синтаксис для стека на `deque` (`append`/`pop`) точно такой же, как и для `list`. Здесь `deque` не дает кардинального преимущества перед списками (ведь `list.append`/`pop` тоже O(1)), но может быть чуть стабильнее по производительности из-за своей внутренней реализации, лишенной редких O(n) переаллокаций `list`. В любом случае, использовать deque для стека — хороший и правильный выбор.
Пример использования deque для очередей (FIFO)
А вот здесь `deque` раскрывается во всей красе! Вспомним нашу проблему с `list.pop(0)` для очереди. С `deque` мы будем использовать `append` для добавления в конец (`enqueue`) и `popleft()` для извлечения из начала (`dequeue`). Обе операции — быстрые O(1).
from collections import deque
import time
import random
# Используем deque как очередь для заданий на печать
printer_queue = deque()
# Моделируем поступление заданий (Enqueue через append)
print("\n--- Моделирование очереди печати ---")
print("Поступают задания:")
for i in range(1, 6): # 5 заданий
job_name = f"Document_{i}.pdf"
printer_queue.append(job_name) # O(1)
print(f" [+] Поступило: '{job_name}'. Очередь: {list(printer_queue)}") # list() для наглядности
time.sleep(random.uniform(0.2, 0.5)) # Имитация паузы между заданиями
# Моделируем работу принтера (Dequeue через popleft)
print("\nПринтер начинает обработку:")
while printer_queue: # Пока очередь не пуста
current_job = printer_queue.popleft() # O(1) - Быстрое извлечение!
print(f" [*] Печатается: '{current_job}'...")
processing_time = random.uniform(0.5, 1.0) # Имитация времени печати
time.sleep(processing_time)
print(f" [✓] Готово: '{current_job}' (за {processing_time:.2f} сек). Осталось в очереди: {len(printer_queue)}")
print("\n--- Очередь печати пуста! Принтер свободен. ---")Ключевой момент здесь — `printer_queue.popleft()`. Эта операция всегда быстрая (O(1)), независимо от того, сколько заданий находится в очереди. Если бы мы использовали `список и list.pop(0)`, каждое извлечение становилось бы все медленнее и медленнее по мере роста начального размера очереди, что совершенно не соответствует реальной логике работы очереди.
Использование deque для очередей — настоятельная рекомендации.
Использование deque для очередей — настоятельная рекомендации.

Когда выбирать deque? Всегда, когда вам критичны быстрые операции на концах последовательности. Если же основной сценарий — это частый произвольный доступ по индексу, то списки остаются лучшим выбором.
Теперь давайте сменим фокус и погрузимся в более теоретическую, но не менее важную концепцию — связанные списки. Это поможет нам понять альтернативные способы организации данных в памяти и подготовит к изучению деревьев и графов.
Связанные списки: зачем понимать узлы и ссылки?🔗
До сих пор мы имели дело со структурами (`list`, `deque`), которые, так или иначе, опираются на идею хранения элементов (или ссылок на них) в непрерывных или блочных участках памяти. Доступ по индексу в списках быстрый именно потому, что мы можем математически вычислить адрес нужной ячейки. `deque` хитро обходит проблему сдвигов, используя блоки и связи между ними.
Связанный список (Linked List) предлагает совершенно иной подход. Забудьте о непрерывных полках или блоках. Представьте себе цепь или гирлянду, где каждое звено (или лампочка) связано только со следующим.
В основе связанного списка лежит понятие узла (node). Каждый узел — это как маленькая коробочка, которая хранит две вещи:
- Данные (data): Собственно полезная информация, которую мы хотим хранить (число, строка, объект — что угодно).
- Ссылка (next): Указатель на следующий узел в цепочке. Это как ниточка, ведущая от одной коробочки к другой.
- Голова (head): Чтобы найти начало всей цепи, у нас есть специальный указатель, который указывает на самый первый узел.
- Конец (tail/None): У самого последнего узла в цепи ссылка next никуда не указывает — она равна None. Это сигнал, что цепочка закончилась.
Визуально это можно представить так:
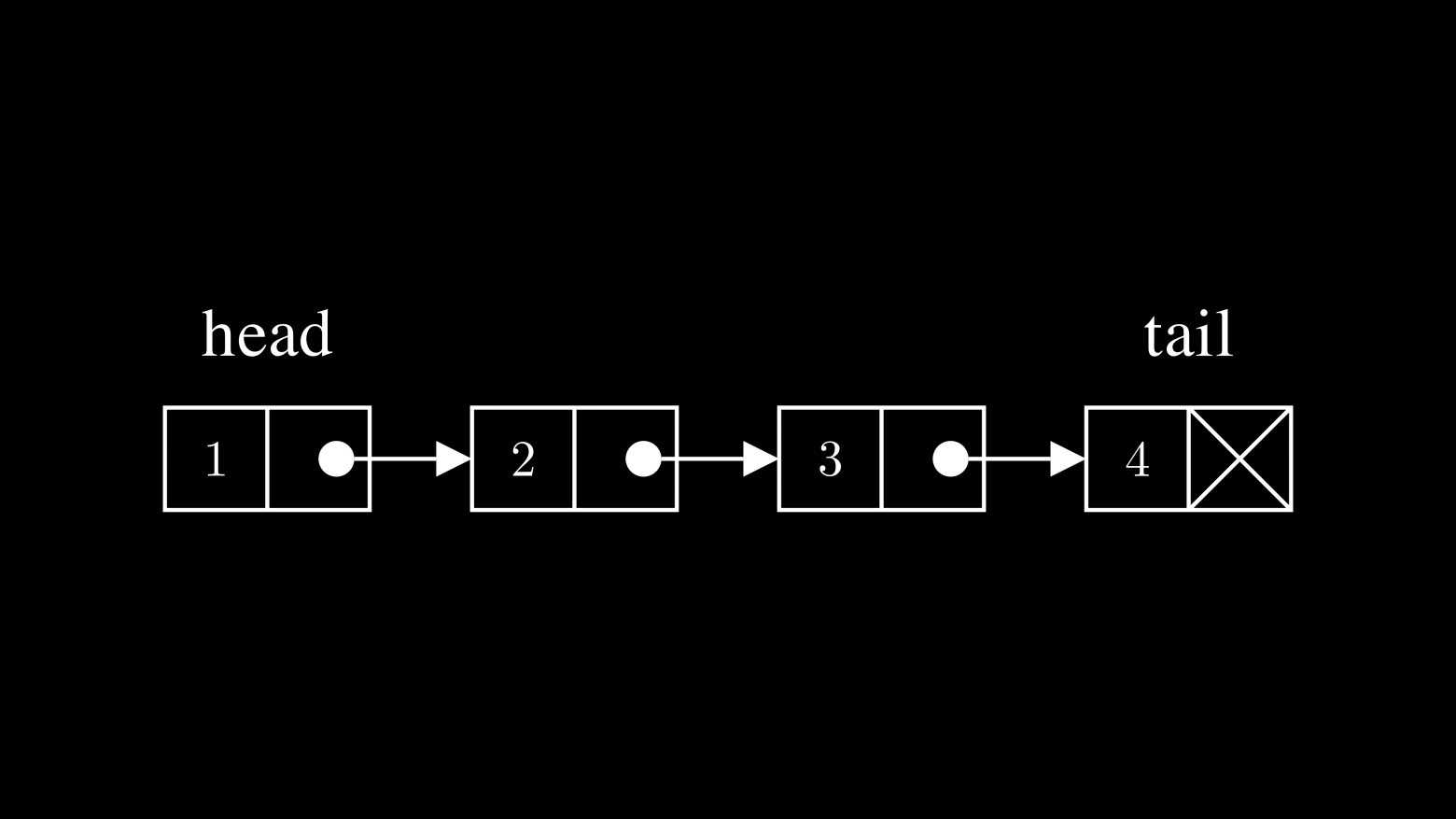
Ключевая идея: узлы не обязаны лежать в памяти рядом друг с другом. Они могут быть разбросаны где угодно. Единственное, что связывает их в последовательность — это цепочка ссылок `next`, идущая от `head` до `None`.
"Зачем мне это в Python, если есть list и deque?" 🤔
Это весьма резонный вопрос. И действительно, в повседневной практике вы будете писать свой собственный класс связанного списка довольно редко. Почему?
- Медленный доступ по индексу. Хотите получить 500-й элемент? Вам придется пройти 500 шагов по ссылкам `next`, начиная от `head`. Это операция O(n), в то время как `list[500]` — это мгновенное O(1).
- Эффективные встроенные типы. списки отлично справляются с доступом по индексу и операциями в конце. `deque` закрывает потребность в быстрых O(1) операциях с обоих концов. Вместе они покрывают подавляющее большинство сценариев работы с линейными последовательностями.
- Управление памятью в Python. В языках типа C/C++ связанные списки ценят за то, что вставка или удаление элемента в середине списка (если у вас уже есть указатель на предыдущий узел) происходит за O(1) без необходимости сдвигать другие элементы. В Python, где памятью управляет сборщик мусора, а `list` и `deque` хорошо оптимизированы, это преимущество не так ярко выражено и часто перекрывается другими недостатками.
- Накладные расходы памяти. Каждый узел хранит не только данные, но и ссылку `next`. Это может привести к большему общему потреблению памяти по сравнению со списком, который хранит только ссылки на данные в непрерывном блоке (хотя список может резервировать лишнее место).
Казалось бы, сплошные минусы для практического применения в Python... Так зачем же мы вообще о них говорим? 🤔
Ценность понимания связанных списков✨
Игнорировать связанные списки — значит упускать важную часть фундамента Computer Science. Вот почему их концепция важна, даже если вы не пишете такие классы каждый день:
- Понимание фундаментальных концепций. Связанные списки — это классический пример структуры данных, основанной на узлах и ссылках (указателях). Работа со связанными узлами помогает понять, как могут быть организованы данные в памяти, как работают ссылки/указатели (пусть и неявные в Python), и как строятся более сложные структуры — деревья и графы.
- Основа для более сложных структур. Многие более продвинутые структуры данных, с которыми вы точно столкнетесь, активно используют концепции узлов и ссылок. Например, деревья строятся из узлов, хранящих данные и ссылки на своих потомков. Графы часто представляют вершинами-узлами, а ребра — ссылками между ними (или хранят связи в списках смежности). Даже некоторые реализации хеш-таблиц внутри используют связанные списки для разрешения коллизий (когда несколько ключей попадают в одну "корзину"). Не поняв, как устроен простой связанный список, будет гораздо сложнее разобраться в устройстве этих более сложных структур.
- Классика собеседований. Вопросы по связанным спискам — стандартная практика на технических собеседованиях во многих IT-компаниях. Часто встречаются задачи вроде: "перевернуть связанный список", "найти его середину", "определить, есть ли в нем цикл" или "слить два отсортированных связанных списка". Эти задачи проверяют не столько знание конкретного синтаксиса, сколько ваше алгоритмическое мышление, умение аккуратно работать со ссылками и обрабатывать крайние случаи (пустой список, список из одного элемента).
- Осознание компромиссов (Trade-offs). Понимая, почему связанный список медленный для доступа по индексу (O(n)), но (теоретически) быстрый для вставки/удаления в середине (O(1), если у вас уже есть ссылка на предыдущий узел), вы начинаете глубже ценить компромиссы, на которые пошли создатели встроенных `list` и `deque`. Это позволяет более осознанно выбирать подходящую структуру данных, понимая ее сильные и слабые стороны не только на уровне "что она умеет", но и "как она это делает и чего это стоит".
- Некоторые алгоритмы и паттерны. Хотя и реже, чем в других языках, концепции связанных списков могут применяться и в Python при реализации некоторых алгоритмов или структур. Яркий пример — LRU Cache (Least Recently Used), который часто реализуется с использованием комбинации хеш-таблицы (для быстрого доступа O(1)) и двусвязного списка (для быстрого перемещения O(1) недавно использованного элемента в "голову" списка). Также концепция может быть релевантна при работе с большими динамическими последовательностями, где вставки/удаления в произвольных местах критичны, хотя в Python для этого чаще ищут другие подходы.
Итог: связанные списки — это не столько инструмент для ежедневного использования, сколько важнейший элемент образования. Это как знать основы алгебры, чтобы понимать высшую математику.
Базовая реализация в Python
Шаг 1: Класс Node — звено цепи. Каждый узел должен хранить данные и ссылку на следующий узел.
class Node:
"""
Представляет узел (звено) односвязного списка.
Хранит данные и ссылку на следующий узел.
"""
def __init__(self, data=None):
self.data = data # Данные, которые хранит узел
self.next = None # Ссылка на следующий узел, по умолчанию None
def __repr__(self):
"""Возвращает строковое представление данных узла.
Удобно при печати всего списка.
"""
return str(self.data)Этот класс очень прост: конструктор (`__init__`) принимает данные и сохраняет их, а поле `next` инициализирует как `None`. Метод `__repr__` нужен для того, чтобы при попытке напечатать узел (или список узлов) мы видели его данные, а не скучный адрес в памяти.
Шаг 2: класс LinkedList. Этот класс будет управлять всей структурой. Как минимум, он должен хранить ссылку на первый узел (`head`). Добавим также возможность инициализировать список из существующей последовательности (например, списка Python) и удобный метод `__repr__` для печати всего списка.
class LinkedList:
"""
Представляет сам односвязный список.
Хранит ссылку на голову (head) и предоставляет базовые операции.
"""
def __init__(self, nodes_data=None):
"""
Инициализирует связанный список.
Может принимать итерируемый объект (например, list, tuple)
для создания узлов списка при инициализации.
"""
self.head = None # Изначально список пуст, головы нет
if nodes_data is not None:
# Пытаемся создать список из переданных данных
try:
# Получаем итератор, чтобы работать с любым итерируемым типом
iterator = iter(nodes_data)
# Создаем голову из первого элемента
first_node_data = next(iterator)
self.head = Node(first_node_data)
current_node = self.head
# Добавляем и связываем остальные элементы
for elem_data in iterator:
current_node.next = Node(elem_data)
current_node = current_node.next # Переходим к только что созданному узлу
except StopIteration:
# Исходный итератор был пуст, self.head останется None
pass
except TypeError:
# Переданный объект неитерируемый
print("Ошибка: Для инициализации LinkedList нужны итерируемые данные.")
self.head = None # Сбрасываем на всякий случай
def __repr__(self):
"""
Возвращает человекочитаемое строковое представление всего списка.
Формат: data1 -> data2 -> ... -> None
"""
nodes_repr = []
current_node = self.head
while current_node is not None:
# Добавляем представление данных текущего узла (используя Node.__repr__)
nodes_repr.append(str(current_node))
current_node = current_node.next # Переходим к следующему узлу
nodes_repr.append("None") # Явно показываем конец списка
return " -> ".join(nodes_repr)В конструкторе `LinkedList` мы проверяем, были ли переданы данные (`nodes_data`). Если да, мы создаем первый узел (`head`), а затем в цикле проходим по остальным данным, создавая новые узлы и связывая их (`current_node.next = ...`). Метод `__repr__` проходит по списку от `head`, собирает строковые представления данных каждого узла и соединяет их стрелочками ->, добавляя None в конце.
Пример создания связанного списка
# 1. Создание пустого списка
empty_llist = LinkedList()
print(f"Пустой список: {empty_llist}")
# 2. Создание узлов и ручное связывание
node1 = Node('A')
node2 = Node('B')
node3 = Node('C')
# Связываем их: A -> B -> C -> None
node1.next = node2
node2.next = node3
# Создаем список и назначаем голову
manual_llist = LinkedList()
manual_llist.head = node1
print(f"Список, связанный вручную: {manual_llist}")
# 3. Создание списка из итерируемого объекта (списка Python)
auto_llist = LinkedList(['Раз', 'Два', 'Три'])
print(f"Список, созданный из list: {auto_llist}")
# 4. Создание из другого итератора (например, range)
range_llist = LinkedList(range(5))
print(f"Список, созданный из range(5): {range_llist}")
# 5. Пример с пустым итератором
empty_init_llist = LinkedList([])
print(f"Список, созданный из []: {empty_init_llist}")Мы научились создавать узлы и связывать их в список, как вручную, так и автоматически при инициализации. Но чтобы сделать со списком что-то полезное (найти элемент, посчитать длину), нам нужно научиться его обходить. Этим и займемся дальше.
Обход связанного списка: шаг за шагом по цепи 🕵️♂️
Обход (или итерация) связанного списка — это фундаментальная операция. Она заключается в последовательном посещении каждого узла, начиная с `head` и двигаясь по ссылкам `next`, пока не дойдем до конца (`None`). Алгоритм очень прост: вы начинаете с "головы" (`head`), используя ее как текущий узел. Далее, в цикле, пока текущий узел существует (то есть не равен `None`), вы выполняете два основных действия: сначала делаете что-то полезное с данными текущего узла (например, печатаете их или сравниваете с искомым значением), а затем переходите к следующему узлу, выполняя присваивание `текущий_узел = текущий_узел.next`. Этот цикл продолжается шаг за шагом, пока вы не достигнете конца списка, где ссылка next окажется `None`.
Это основа для поиска, подсчета элементов, преобразования списка и многих других операций.
Реализуем итератор
В Python самый удобный способ обхода любой последовательности — это цикл `for ... in ...`. Чтобы наш `LinkedList` его поддерживал, нам нужно реализовать специальный метод `__iter__`. Этот метод должен возвращать итератор — объект, который умеет отдавать следующий элемент по запросу.
Самый элегантный способ создать итератор в Python — использовать ключевое слово `yield`. Функция или метод, содержащий `yield`, становится генератором. При каждом вызове `yield` он "замораживает" свое состояние и возвращает значение. При следующем обращении к нему он "размораживается" и продолжает выполнение с того места, где остановился.
Давайте добавим метод `__iter__` в наш класс `LinkedList`:
class Node:
""" Узел связанного списка (без изменений) """
def __init__(self, data=None):
self.data = data
self.next = None
def __repr__(self):
return str(self.data)
class LinkedList:
""" Сам связанный список """
def __init__(self, nodes_data=None):
self.head = None
# ... (код инициализации из предыдущего шага без изменений) ...
if nodes_data is not None:
try:
iterator = iter(nodes_data)
first_node_data = next(iterator)
self.head = Node(first_node_data)
current_node = self.head
for elem_data in iterator:
current_node.next = Node(elem_data)
current_node = current_node.next
except StopIteration: pass
except TypeError:
print("Ошибка: Для инициализации LinkedList нужны итерируемые данные.")
self.head = None
def __repr__(self):
""" Представление списка (без изменений) """
nodes_repr = []
current_node = self.head
while current_node is not None:
nodes_repr.append(str(current_node))
current_node = current_node.next
nodes_repr.append("None")
return " -> ".join(nodes_repr)
# !!! ВОТ ОН, НАШ ИТЕРАТОР !!!
def __iter__(self):
"""
Позволяет итерироваться по данным узлов списка
с помощью стандартного цикла for.
"""
current = self.head # Начинаем с головы
while current is not None:
yield current.data # Возвращаем данные текущего узла
current = current.next # Переходим к следующемуМетод `__iter__` очень лаконичен: он просто проходит по списку от `head` до `None` и на каждом шаге `yield`-ит (отдает) данные (`current.data`) текущего узла.
Пример использования итератора:
Теперь мы можем легко пройтись по нашему списку с помощью `for`:
Пример использования итератора:
Теперь мы можем легко пройтись по нашему списку с помощью `for`:
# Создадим плейлист
my_playlist = LinkedList(["The Beatles", "Queen", "Led Zeppelin", "Pink Floyd"])
print(f"Мой плейлист: {my_playlist}")
print("\nВоспроизводим треки (итерация с помощью for):")
for track in my_playlist: # Теперь это работает благодаря __iter__!
print(f" 🎶 Сейчас играет: {track}")
# Мы можем использовать и другие конструкции, ожидающие итерируемый объект:
playlist_list = list(my_playlist) # Преобразовать в обычный список Python
print(f"\nПлейлист как Python list: {playlist_list}")
playlist_tuple = tuple(my_playlist) # Преобразовать в кортеж
print(f"Плейлист как tuple: {playlist_tuple}")
# Посчитаем длину "питоничным" способом (хотя это O(n) под капотом!)
length = len(playlist_list) # len() работает со списком, полученным из итератора
# Или можно было бы реализовать __len__ в LinkedList, который бы делал обход
print(f"Количество треков: {length}")Вывод:
Мой плейлист: The Beatles -> Queen -> Led Zeppelin -> Pink Floyd -> None
Воспроизводим треки (итерация с помощью for):
🎶 Сейчас играет: The Beatles
🎶 Сейчас играет: Queen
🎶 Сейчас играет: Led Zeppelin
🎶 Сейчас играет: Pink Floyd
Плейлист как Python list: ['The Beatles', 'Queen', 'Led Zeppelin', 'Pink Floyd']
Плейлист как tuple: ('The Beatles', 'Queen', 'Led Zeppelin', 'Pink Floyd')
Количество треков: 4Сложность обхода:
Независимо от того, как реализован обход (через `__iter__` или отдельный метод), чтобы посетить все `n` узлов списка, нам нужно сделать n шагов. Поэтому временная сложность обхода связанного списка всегда O(n).
Зачем нужен обход?
Как мы уже упоминали, обход — это основа для почти всех операций со связанными списками, которые требуют доступа к элементам не только в голове списка:
Независимо от того, как реализован обход (через `__iter__` или отдельный метод), чтобы посетить все `n` узлов списка, нам нужно сделать n шагов. Поэтому временная сложность обхода связанного списка всегда O(n).
Зачем нужен обход?
Как мы уже упоминали, обход — это основа для почти всех операций со связанными списками, которые требуют доступа к элементам не только в голове списка:
- Поиск элемента: Обходим список, сравнивая `current.data` с искомым значением.
- Вычисление длины: Обходим список, увеличивая счетчик на каждом шаге.
- Преобразование в другие структуры: Как мы видели, `list(my_linked_list)` использует обход.
- Вставка/удаление в произвольном месте: Сначала нужно дойти до нужного места с помощью обхода, а потом уже переназначать ссылки next. (Реализацию этих операций мы оставим за рамками этой статьи, чтобы не раздувать ее, но важно понимать, что обход — первый шаг).
Итог: Хотя вы не будете писать `class LinkedList` каждый день, работая на Python, потраченное время на понимание их концепции окупится сторицей. Это знание расширяет ваш кругозор, помогает глубже понять другие структуры данных и алгоритмы, а также подготовит вас к каверзным вопросам на собеседованиях. Считайте это необходимой теоретической базой для любого серьезного разработчика.
Заключение: знание о новых инструментах 🛠️🧠
Вторая часть нашего путешествия по структурам данных Python подошла к концу! Мы сделали важный шаг вперед от базовых встроенных типов, рассмотрев два очень разных, но по-своему полезных подхода к работе с последовательностями.
Ключевой вывод: Не существует "идеальной" структуры данных на все случаи жизни. Выбор всегда зависит от конкретной задачи и требований к производительности для разных операций. `deque` бьет `list` на операциях с начала, но проигрывает в доступе по индексу. Связанный список (теоретически) выигрывает при вставке в середину, но ужасен для поиска. Понимание этих компромиссов и внутреннего устройства — ключ к написанию по-настоящему эффективного кода.
Что нас ждет в части 3?
Мы переключимся с хранения данных на способы их обработки и решения задач:
Мы переключимся с хранения данных на способы их обработки и решения задач:
- Рекурсия: Разберем эту элегантную (и иногда опасную 😈) технику, поймем стек вызовов и типичные подводные камни.
- Динамическое программирование (ДП): Научимся оптимизировать рекурсивные (и не только) решения с помощью мемоизации и табуляции, чтобы избегать повторных вычислений и решать задачи, которые иначе были бы неподъемными.