Машинное обучение быстро меняет мир, охватывая разнообразные области применения в промышленности и научных сферах. Оно влияет на все сферы нашей повседневной жизни: от голосовых помощников для назначения встреч, проверки календаря и воспроизведения музыки, до рекламы, которая настолько точна, что иногда может предсказать, что нам понадобится, ещё до того, как мы об этом подумаем.
Введение в машинное обучение
Что такое машинное обучение?
Считается, что компьютерная программа учится на опыте E в отношении некоторого класса задач T и меры производительности P, если её производительность на задачах в T, измеряемая P, улучшается с опытом E.Том М. Митчелл
Машинное обучение можно сравнить с развитием ребёнка. По мере роста увеличивается его опыт (E) в выполнении задачи (T), что приводит к повышению производительности (P).
Например, мы даем ребёнку игрушку, в которой есть разные формы и отверстия под эти фигуры. В этом задача (Т) ребёнка заключается в том, чтобы найти подходящее отверстие для фигуры. Ребёнок изучает фигуру и пытается поместить её в отверстие. Допустим, у этой игрушки три формы: круг, треугольник и квадрат. При первой попытке найти отверстие для фигуры показатель эффективности (P) равен 1/3, что означает, что ребенок нашёл 1 из 3 правильных отверстий для фигуры.
Затем ребёнок пробует ещё и замечает, что у него есть небольшой опыт в этом задании. Учитывая полученный опыт (Е), ребёнок пробует выполнить это задание ещё раз, и результативность (Р) теперь оказывается равна 2/3. Повторив это задание (Т) 100 раз, ребёнок знает, какая фигура входит в какое отверстие.
Таким образом, опыт (E) увеличился, производительность (P) также увеличилась, и мы замечаем, что по мере увеличения количества попыток производительность также увеличивается, что приводит к повышению точности.
Это очень похоже на машинное обучение. Машина берет задачу (T), выполняет её и измеряет производительность (P). Теперь у машины есть большое количество данных, поэтому по мере обработки этих данных её опыт (E) со временем увеличивается, что приводит к повышению производительности (P). Таким образом, после обработки всех данных точность нашей модели машинного обучения возрастает, что означает, что прогнозы, сделанные нашей моделью, будут очень точными.
Вот ещё одно определение машинного обучения, данное Артуром Самуэлем:
Машинное обучение — это область компьютерной науки, которая даёт «компьютерам способность обучаться без явного программирования».Артур Самуэль
Давайте попробуем его понять. «Обучаться без явного программирования» — означает, что мы не собираемся обучать компьютер с помощью определённого набора правил, а вместо этого мы собираемся снабдить его достаточным количеством данных и дать ему время научиться на них, совершая собственные ошибки и совершенствуясь на них. Например, мы не учили ребёнка, как вставлять фигуры в игрушку, но, выполняя одно и то же задание несколько раз, он научился этому самостоятельно.
Поэтому можно сказать, что мы не учили ребёнка в явном виде, как сортировать фигуры. Мы делаем то же самое с машинами. Мы даём ей достаточно данных для работы и снабжаем её информацией, которую мы хотим от неё получить. Таким образом, она обрабатывает данные и точно прогнозирует их.
Зачем нам машинное обучение?
Допустим, у нас есть набор изображений кошек и собак. Мы хотим классифицировать их в группы: кошки и собаки. Для этого нам нужно найти различные признаки животных, такие как:
- Сколько глаз у каждого животного?
- Какого цвета глаза у каждого животного?
- Каков рост каждого животного?
- Каков вес каждого животного?
- Чем обычно питается каждое животное?
Мы формируем вектор по ответам на каждый из этих вопросов. Далее мы применяем набор правил:
Если рост > 1 фута и вес > 15 фунтов, то это может быть кошка
Теперь мы должны составить такой набор правил для каждого класса в данных. По сути мы создаем дерево решений из утверждений if, elif, ... else и проверяем, попадает ли объект в одну из категорий.
Предположим, что результат этого эксперимента не был удовлетворительным, поскольку многие животные были классифицированы неправильно. Это дает нам прекрасный повод использовать машинное обучение.
Машинное обучение обрабатывает данные с помощью различных алгоритмов и говорит нам, какой признак более важен для определения того, кошка это или собака. Таким образом, вместо того чтобы применять множество наборов правил, мы можем упростить их на основе двух или трех признаков, и в результате это даёт нам более высокую точность. Предыдущий метод не был достаточно обобщающим, чтобы делать предсказания.
Модели машинного обучения помогают нам в решении многих задач:
- распознавание объектов;
- обобщение;
- прогнозирование;
- классификация;
- кластеризация№
- рекомендательные системы;
- и другое.
Основные алгоритмы машинного обучения
Регрессия
Мы используем алгоритмы регрессии для прогнозирования непрерывных значений.
Примеры алгоритмов регрессии:
- Линейная регрессия
- Полиномиальная регрессия
Классификация
Такие алгоритмы нужны для предсказания классов объектов.
Примеры алгоритмов классификации:
- Метод К-ближайших соседей
- Деревья решений
- Случайный лес
- Метод опорных векторов
- Наивный байесовский алгоритм
Кластеризация
Алгоритмы кластеризации используются для структурирования объектов в данных на группы.
Примеры алгоритмов кластеризации:
- Метод К-средних
- DBSCAN (Density-based spatial clustering of applications with noise)
- Mean Shift
- Иерархический
Ассоциация
Алгоритмы ассоциации используются для объединения совпадающих элементов или событий.
Пример алгоритма ассоциации:
- Apriori
Обнаружение аномалий
Обнаружение аномалий используется для выявления необычных действий и объектов, например, для выявления мошенничества.
Снижение размерности
Снижение размерности используется для уменьшения объёма данных, чтобы извлечь из набора только полезные признаки.
Рекомендательные системы
Позволяют находить наиболее подходящие предложения для пользователей или клиентов. Например:
- Рекомендательная система Netflix
- Система рекомендаций книг
- Система рекомендаций товаров на Amazon
В настоящее время очень уж нашумели словосочетания вроде «искусственный интеллект», «машинное обучение», «глубокое обучение» и другие.
В чём фундаментальные различия между искусственным интеллектом, машинным обучением и глубоким обучением?
Искусственный интеллект (ИИ), по определению профессора Эндрю Мура, — это наука и способ проектирования, позволяющие заставить компьютеры вести себя так, как (до недавнего времени) мы считали ведёт себя человеческий разум.
Сюда относится:
- компьютерное зрение;
- обработка естественного языка;
- креативность;
- обобщение.
Согласно определению профессора Тома Митчелла, машинное обучение (ML) относится к научной ветви ИИ, которая фокусируется на изучении компьютерных алгоритмов, позволяющих компьютерным программам автоматически совершенствоваться благодаря полученному опыту.
Это включает:
- классификацию;
- нейронные сети;
- кластеризацию.
Глубокое обучение — это подкатегория машинного обучения, в которой многоуровневые нейронные сети в сочетании с высокой вычислительной мощностью и большими массивами данных позволяют создавать мощные модели машинного обучения.
Почему именно Python используется для реализации алгоритмов машинного обучения?
Python — это популярный язык программирования широкого назначения. Причина популярности Python среди специалистов по работе с данными заключается в том, что в этом ЯП уже реализовано множество разнообразных модулей и библиотек, которые делают нашу жизнь более комфортной.
Давайте вкратце рассмотрим некоторые полезные библиотеки.
- Numpy. Это математическая библиотека для работы с многомерными массивами в Python. Она позволяет делать вычисления эффективно и быстро.
- Scipy. Эта библиотека представляет собой коллекцию численных алгоритмов и инструментов, разработанных для конкретных задач, таких как обработка сигналов, оптимизация, статистика и многие другие. Scipy — это функциональный инструмент для научных и высокопроизводительных вычислений.
- Matplotlib. Это популярный пакет для построения 2D и в 3D-графиков.
- Scikit-learn. Это библиотека для машинного обучения. В ней уже реализовано большинство алгоритмов классификации, регрессии и кластеризации, а ещё она совместима с нужными библиотеками такими как Numpy, Scipy.
Алгоритмы машинного обучения делятся на две группы:
- Обучение с учителем
- Обучение без учителя
Обучение с учителем и без
Обучение с учителем
Цель: предсказать значение или класс
Обучение с учителем — это важная часть машинного обучения, возможно, даже основная на данный момент. Этот метод позволяет нам создавать функции на основе размеченных обучающих данных, которые представляют собой множество пар, состоящих из признаков и целевых величин. Признаки — это описательные характеристики объектов, а целевая величина — это то, что мы хотим предсказать.
В зависимости от типа целевой величины, мы можем условно разделить обучение с учителем на две типа задач: классификация и регрессия. Классификация подразумевает категориальные целевые переменные, что находит применение в широком спектре задач — от простых, таких как классификация изображений, до более сложных, например, машинный перевод. Регрессия подразумевает непрерывные целевые переменные и применяется для прогнозирования акций, погоды, спроса и других задач.
Чтобы лучше понять, что такое обучение с учителем, давайте рассмотрим простой пример. Дадим ребёнку 100 картинок с животными, по десять каждого вида: например десять львов, десять обезьян, десять слонов и т.д. Затем научим ребёнка распознавать виды животных по различным характеристикам (признакам). Например, если цвет животного жёлтый, то это может быть лев. Если это большое животное с хоботом, то это может быть слон.
Этот процесс обучения ребёнка различать животных можно считать примером обучения с учителем. После обучения ребёнок может самостоятельно определять вид животного. Если 8 из 10 классификаций были правильными, мы можем сказать, что ребёнок проделал довольно хорошую работу. То же самое относится и к машинам.
Мы предоставляем тысячи объектов с их реальными классами (размеченные данные — это данные, для которых мы знаем целевую величину). Затем машина обучается на основе имеющихся характеристик. После обучения мы можем использовать нашу модель для составления прогнозов.
Примеры алгоритмов обучения с учителем:
- Линейная регрессия
- Логистическая регрессия
- Метод K-ближних соседей
- Дерево решений
- Случайный лес
- Метод опорных векторов
Обучение без учителя
Цель: Найти паттерны в данных, сгруппировать их.
В отличие от метода выше, в обучении без учителя на основе неразмеченных данных определяется функция, которая описывает скрытые в них структуры.
Пожалуй, основными типами такого обучения являются методы уменьшения размерности, такие как PCA, t-SNE, при этом PCA обычно используется для предварительной обработки данных, а t-SNE — для их визуализации.
Также есть алгоритмы кластеризации, которая исследует скрытые закономерности в данных и затем группирует объекты. К таким алгоритмам относятся K-средних, иерархическая кластеризация и другие.
Обучение может быть полезным, поскольку оно освобождает нас от необходимости вручную размечать данные. Говоря о глубоком обучении, мы рассматриваем два вида инструментов обучения без учителя: обучение представлений и генеративные модели.
Обучение представлений направлено на выделение высокоуровневого репрезентативного признака, полезного для решения дальнейших задач. Генеративные же модели предназначены для создания новых данных на основе некоторых характеристик.
В алгоритмах обучения без учителя у нас нет размеченных данных, поэтому машине приходится обрабатывать входные данные и пытаться сделать выводы о выводе. Например, помните ребёнка, которому мы дали сортер? В этом случае он будет учиться на собственных ошибках, чтобы найти идеальное отверстие для разных фигур.
Соль в том, что мы не учим ребёнка методам подбора фигур. Он сам учится на различных характеристиках игрушки и пытается сделать выводы о них. Короче говоря, предсказания основаны на неразмеченных данных.
Примеры алгоритмов обучения без учителя:
- Уменьшение размерности
- Оценка плотности
- Генеративно-состязательные сети (GAN)
- Кластеризация
В этом материале мы рассмотрим примеры регрессии с кодом на Python
Линейная регрессия
Линейная регрессия — это статистический подход, который моделирует взаимосвязь между входными признаками и целевой величиной. Входные признаки также называются независимыми переменными, а целевая величина — зависимой переменной. Наша цель — предсказать значение зависимой переменной на основе признаков путём умножения их на оптимальные коэффициенты.
Некоторые реальные примеры использования линейной регрессии:
- прогнозирование продаж продукции.
- прогнозирование экономического роста.
- прогнозирование цен на нефть.
- оценка влияния среднего балла аттестата на вероятность поступление в колледж.
Существует два типа линейной регрессии:
- Простая линейная регрессия
- Множественная линейная регрессия
Простая линейная регрессия
В простой линейной регрессии мы прогнозируем зависимую переменную на основе только одного входного признака. Простая линейная регрессия имеет вид:
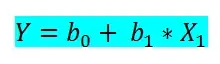
где:
- b0 — независимый коэффициент,
- b1 — коэффициент для признака,
- x1 — входной признак,
- Y — целевая величина.
Ниже реализуем простую линейную регрессию с помощью библиотеки sklearn в Python.
Импортируем необходимые библиотеки:
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from sklearn.linear_model import LinearRegressionПрочитаем CSV-файл. Используем набор данных Softlayer IBM.
data = pd.read_csv('https://s3-api.us-geo.objectstorage.softlayer.net/cf-courses-data/CognitiveClass/ML0101ENv3/labs/FuelConsumptionCo2.csv')
data.head()Теперь выберем столбцы, которые будем использовать для прогноза. Здесь наша цель — предсказать значение выбросов CO2 ("co2 emissions") по значению размера двигателя ("engine size").
data = data[['ENGINESIZE', 'CO2EMISSIONS']]Строим график зависимости:
plt.scatter(data['ENGINESIZE'], data['CO2EMISSIONS'])
plt.xlabel('ENGINESIZE')
plt.ylabel('CO2EMISSIONS')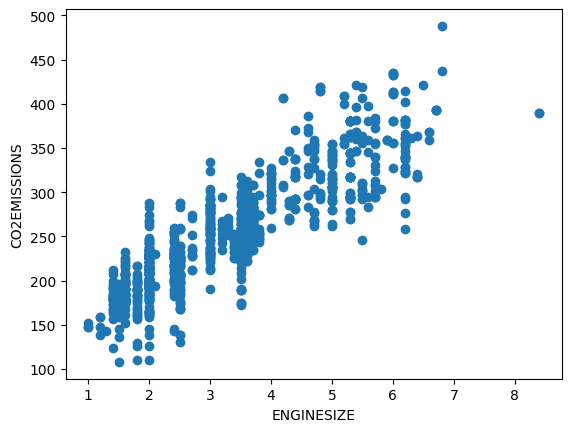
Теперь нам необходимо разделить выборку на тренировочную и тестовую части. Мы будем использовать тренировочные данные для обучения нашей модели, а затем проверим качество нашей модели с помощью тестового набора данных.
from sklearn.model_selection import train_test_split
train_x, test_x, train_y, test_y = train_test_split(data['ENGINESIZE'], data['CO2EMISSIONS'], test_size=0.2, random_state=42)И теперь обучаем модель. Это сводится к нахождению коэффициентов для оптимальной линии регрессии.
regr = LinearRegression()
regr.fit(train_x, train_y)
print('Коэффициент:', regr.coef_)
print('Intercept:', regr.intercept_)
# Коэффициент: [38.99297872]
# Intercept: 126.28970217408721pt_)На основе коэффициентов мы можем построить линию наилучшего соответствия для этого набора данных:
plt.scatter(data['ENGINESIZE'], data['CO2EMISSIONS'])
plt.plot(train_x, regr.coef_ * train_x + regr.intercept_, '-r')
plt.xlabel('ENGINESIZE')
plt.ylabel('CO2EMISSIONS')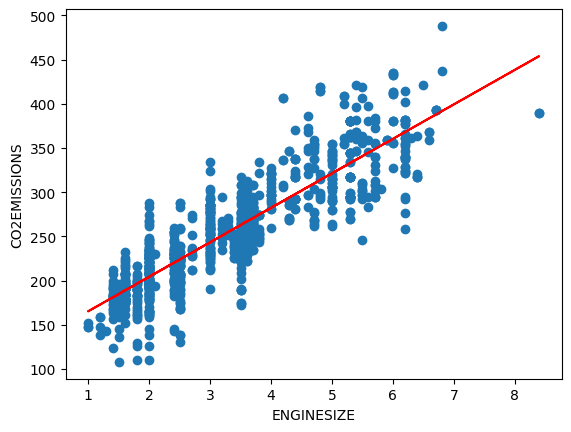
И делаем прогноз значений выбросов СО2 на основе объема двигателя.
engine_size = 3.5
regr.predict([[engine_size]])
# array([262.76512771])На стоит проверить качество модели на тестовом наборе данных, сравним фактические значения с полученными прогнозами:
from sklearn.metrics import r2_score
test_y_pred = regr.predict(test_x)
print('R^2:', r2_score(test_y, test_y_pred))
# R^2: 0.7615595731934373Многомерная линейная регрессия
В простой линейной регрессии мы могли учитывать только один входной признак для прогнозирования. Однако в многомерной линейной регрессии мы можем предсказать целевую величину на основе более чем одного признака. Вот формула для многомерной линейной регрессии:
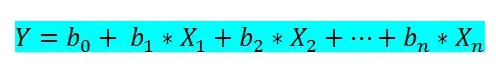
где:
Определяем X и y и теперь будем использовать все признаки:
- b0 — независимый коэффициент,
- b1, b2, bn — коэффициенты для признаков,
- x1, x2, xn — признаки,
- Y — прогнозируемая величина.
Определяем X и y и теперь будем использовать все признаки:
X = data[['ENGINESIZE', 'CYLINDERS', 'FUELCONSUMPTION_COMB', 'FUELCONSUMPTION_CITY', 'FUELCONSUMPTION_HWY', 'FUELCONSUMPTION_COMB_MPG']]
y = data['CO2EMISSIONS']Разделяем выборки на train и test:
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
Обучаем модель:
regr = LinearRegression()
regr.fit(X_train, y_train)Находим коэффициенты для признаков:
coef_df = pd.DataFrame(regr.coef_, X.columns, columns=['Coefficient'])
coef_df.loc['Intercept'] = regr.intercept_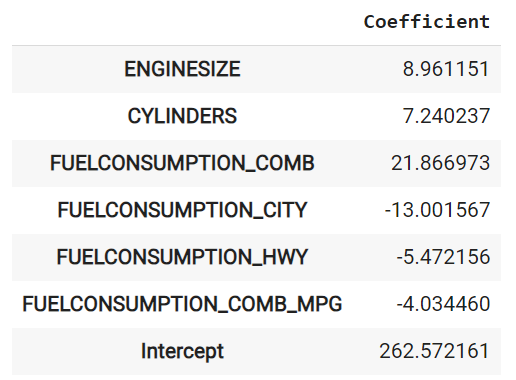
Делаем прогноз:
y_pred = regr.predict(X_test)
print('R^2:', r2_score(y_test, y_pred))
# R^2: 0.9034041224574012Качество многомерной линейной регрессии получилось намного выше, чем простой линейной регрессии.
Полиномиальная регрессия
Иногда у нас есть данные, которые не следуют линейной тенденции, а связи между ними нелинейные. Поэтому мы будем использовать полиномиальную регрессию.
Прежде чем перейти к реализации, давайте посмотрим, как выглядят стандартные графики нелинейных функций.
Полиномиальные функции и их графики
График для Y=X:
X = np.arange(-10, 10)
y = X
plt.scatter(X, y)
График для Y = X²:
X = np.arange(-10, 10)
y = np.power(X, 2)
plt.scatter(X, y)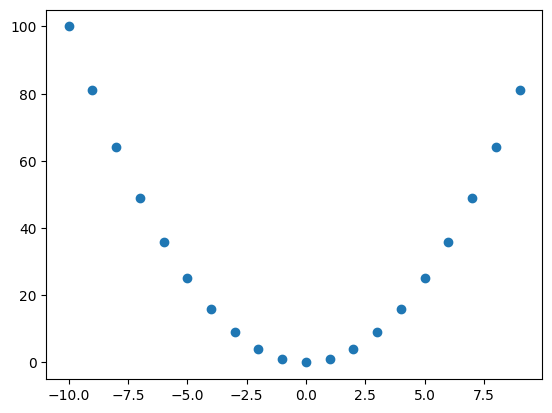
График для Y = X³:
X = np.arange(-10, 10)
y = np.power(X, 3)
plt.scatter(X, y)
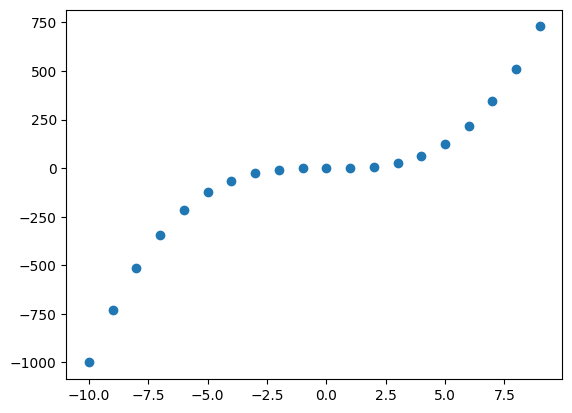
График с более чем одним многочленом: Y = X³+X²+X:
X = np.arange(-10, 10)
y = np.power(X, 3)
y1 = np.power(X, 3) + np.power(X, 2) + X
plt.scatter(X, y, c='red')
plt.scatter(X, y1, c='green')
На графике выше зелёные точки показывают график для Y=X³+X²+X, а красные точки показывают график для Y = X³.
Ниже приведена формула полиномиальной регрессии в общем виде:
Ниже приведена формула полиномиальной регрессии в общем виде:
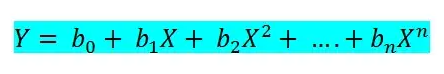
где:
Y — целевая величина,
X — признаки,
b0, b1, bn — коэффициенты.
Давайте при помощи класса PolynomialFeatures добавим в наши данные полиномиальные признаки:
Y — целевая величина,
X — признаки,
b0, b1, bn — коэффициенты.
Давайте при помощи класса PolynomialFeatures добавим в наши данные полиномиальные признаки:
from sklearn.preprocessing import PolynomialFeatures
poly = PolynomialFeatures(degree=2)
X_train_poly = poly.fit_transform(X_train)
X_test_poly = poly.fit_transform(X_test)Сделаем прогноз на основе этих данных и оценим результат:
regr = LinearRegression()
regr.fit(X_train_poly, y_train)
y_pred = regr.predict(X_test_poly)
print('R^2:', r2_score(y_test, y_pred))
# R^2: 0.9264359939595689568Качество получилось ещё выше!
Про полиномиальную регрессию можете поподробнее почитать здесь 👈🏻
Источник: Towards AI