
Предположим, вы столкнулись с ситуацией, когда вам нужно сдвинуть все строки в датафрейме или вы хотите вычислить разницу в последовательных рядах. Метод shift() библиотеки pandas вам в помощь.
Сдвиг значений с помощью periods
Метод shift() сдвигает индексы в датафрейме на нужное количество значений. Простейший вызов этой функции должен содержать аргумент periods (по умолчанию periods=1), который представляет собой количество шагов сдвига для нужной оси. По умолчанию сдвигаются значения по вертикали вдоль оси 0. Отсутствующие значения, появившихся в результате сдвига, будут автоматически заполнены NaN.
Давайте посмотрим, как это работает, на примере. Создадим датафрейм:
df = pd.DataFrame({
"A": [1, 2, 3, 4, 5],
"B": [10, 20, 30, 40, 50]
})Сдвинем индекс на 1 строку по вертикали:
df.shift(periods=1)Так тоже можно:
df.shift(1)
Для замены NaN можно использовать аргумент fill_value и проставить вместо пропусков 0:
df.shift(periods=1, fill_value=0)
Кроме того, в periods можно передавать отрицательные числа, чтобы сдвигать значения в противоположном направлении.

Чтобы сдвинуть значения по горизонтали, можно задать axis=1:
df.shift(periods=1, axis=1)
Сдвиг данных временного ряда с помощью freq
У метода shift() также есть аргумент freq. он позволяет выполнять сдвиг на основе некоей заданной частоты, что полезно при работе с данными временных рядов.
Чтобы использовать аргумент freq, необходимо убедиться, что индексами в датафрейме являются типы date или datetime, иначе возникнет ошибка NotImplementedError.
Давайте рассмотрим это на примере:
df = pd.DataFrame({
"A": [1, 2, 3, 4, 5],
"B": [10, 20, 30, 40, 50]
},
index=pd.date_range("2020-01-01", freq="D", periods=5)
)Сдвинем индекс на 10 дней:
df.shift(freq='10D')
# эквивиалент:
df.shift(periods=10, freq="D")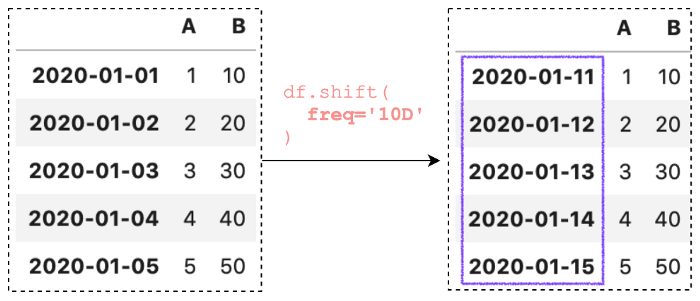
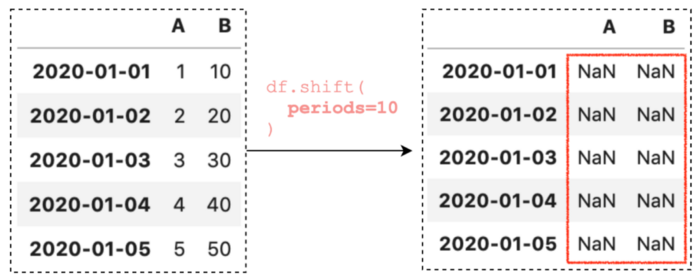
При выполнении той же операции с помощью только одного аргумента periods вы получите следующий результат. Конечно, это не то, чего мы хотим.
Вычисление разницы по последовательным значениям временного ряда
Предположим, вам нужно использовать значение предыдущего ряда для расчёта чего-либо. Тут тоже пригодится метод shift():
df = pd.DataFrame({
"date": pd.date_range("2020-01-01", freq="D", periods=5),
"sales": [22, 30, 32, 25, 42]
})
Рассчитаем изменение продаж по последовательным значениям:
df["diff"] = df["sales"] - df.shift(1)["sales"]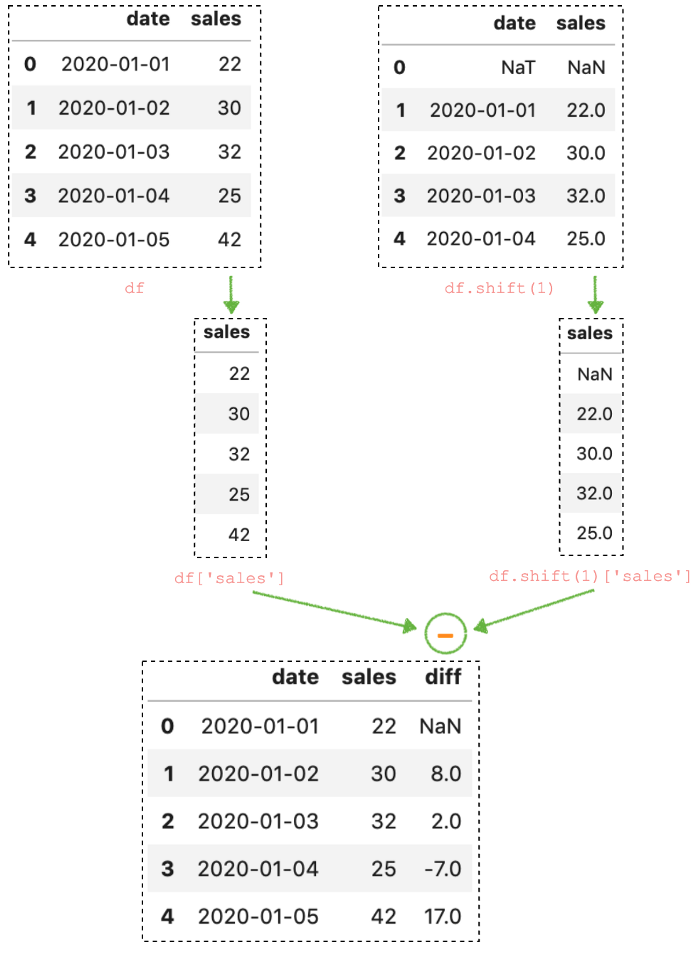
Короче, эта функция крайне полезна при работе с временными рядами. Давайте рассмотрим ещё один практический пример.
Вычисление разницы для временного ряда
Теперь предположим, что вас попросили рассчитать изменение продаж за 7 дней следующим образом:
value_1 = Day_8 - Day_1
value_2 = Day_9 - Day_2
value_3 = Day_10 - Day_3
...
value_n = Day_N - Day_N-7Использование метода shift() с аргументом freq — идеальный способ решения этой задачи. Давайте воспользуемся методом read_csv() (пример данных здесь) с аргументами parse_dates и index_col для формирования датафрейма.
df = pd.read_csv(
"https://raw.githubusercontent.com/obulygin/content/main/pandas_shift/time_series.csv",
parse_dates=["date"],
index_col=["date"],
)
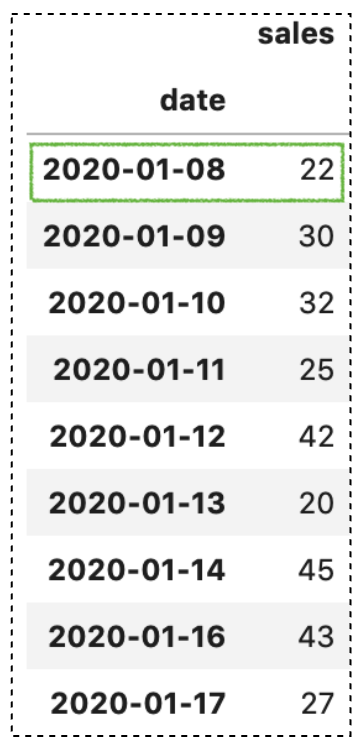
Обратите внимание, что запись для "2020-01-08" отсутствует. Выполнив df.shift(freq='7D'), вы должны получить результат с записью для "2020-01-08".
Затем мы можем рассчитать изменение продаж за 7 дней:
the_7_days_diff = df["sales"] - df.shift(freq="7D")["sales"]
Обратите внимание:
- в результате есть запись для "2020-01-08";
- значение "2020-01-08" — NaN, потому что изначально в данных не было такого значения;
- значения для даты с "2020-01-01" по "2020-01-07" — NaN, потому что их нет и в df.shift(freq='7D');
- последние 6 записей — NaN, потому что в датафрейме не было этих значений.
Заключение
Метод shift() может быть очень полезен, когда нужно сдвинуть все строки в датафрейме или требуется использовать предыдущую строку для вычислений. А ещё он применяется при работе с данными временных рядов.
Рекомендуем также ознакомиться с документацией метода.
Источник: Towards Data Science