
16 сентября 2025 года в мире AI-агентов произошло событие, которое многие могли пропустить за потоком новостей, но которое, на мой взгляд, имеет все шансы стать поворотной точкой. Tongyi Lab, подразделение Alibaba, не просто выпустила очередную модель. Они выложили в полный open-source Tongyi DeepResearch — веб-агента для сложных исследований, который по метрикам не уступает проприетарным решениям от OpenAI.
Но главная бомба здесь не в самой модели. Главное — Alibaba сдали все карты и показали полную, от начала до конца, методологию создания таких агентов. Они, по сути, открыли исходники не просто продукта, а целого завода по их производству.
В этой статье мы подробно разберем, что же такого особенного в Tongyi DeepResearch, почему их подход к обучению и работе агентов решает фундаментальные проблемы, и как вы можете сами это попробовать.
Что такое Tongyi DeepResearch?
Если коротко, Tongyi DeepResearch — это автономный AI-агент, созданный для решения сложных задач по поиску и анализу информации в вебе. Представьте, что вам нужно не просто найти ответ на вопрос "какая столица у Франции?", а провести исследование вроде: "Проанализируй влияние последних изменений в европейском законодательстве о конфиденциальности данных на малые e-commerce стартапы в Германии и сравни с ситуацией в США". Это задача для DeepResearch.
Но почему это событие, а не очередной релиз?
- Производительность на уровне лучших: Модель показывает state-of-the-art результаты, обходя все существующие open-source аналоги и выступая наравне с закрытыми системами.
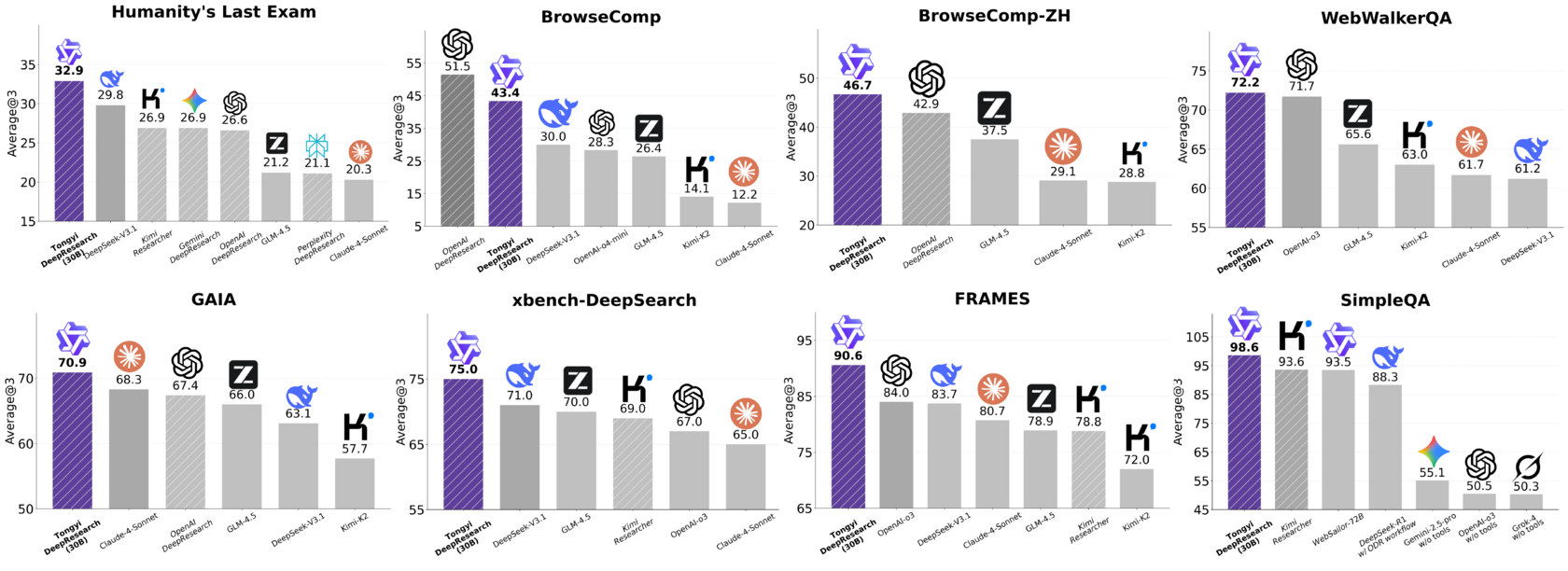
- Полностью открытый исходный код: Вы получаете не только веса модели (
Tongyi-DeepResearch-30B-A3B— это MoE-модель с 30.5B параметров, из которых активны 3.3B), но и весь код, данные и, что самое ценное, — методологию. - Инновационный подход к обучению и работе: Вот здесь и кроется магия. Разработчики переосмыслили весь жизненный цикл агента, от данных для предобучения до логики его работы в рантайме.
Именно этот последний пункт делает релиз таким значимым. Давайте копнем глубже.
Главный секрет — не модель, а полный цикл обучения
Alibaba представила целостную парадигму Agentic CPT → Agentic SFT → Agentic RL, создав замкнутый цикл обучения AI-агента. Это как конвейер, где на входе — сырая базовая модель, а на выходе — специалист по исследованиям.
Этап 1: Agentic Continual Pre-training (CPT) — Создание "агентного" фундамента
Вместо того чтобы брать стандартную LLM и доучивать ее под агентские задачи, команда Tongyi Lab ввела концепцию Agentic Continual Pre-training (CPT) — это процесс постоянного дообучения базовой модели на огромных массивах синтетических агентских данных.
Для этого они создали AgentFounder — систему, которая генерирует данные, имитирующие взаимодействие агента с инструментами (например, поиском). Это не просто тексты, а структурированные записи вида "вопрос-ответ-действие".
[!INFO] Что это значит на практике? Модель с самого начала "привыкает" к формату работы агента. Она учится не просто генерировать текст, а мыслить в парадигме "мысль -> действие -> наблюдение". Это создает мощный "агентный" фундамент, на который гораздо легче ложатся последующие стадии обучения.
Этап 2: Supervised Fine-Tuning (SFT) — Холодный старт для сложных задач
После того как модель получила базовые "агентские" навыки, ее нужно научить решать сложные, многошаговые задачи. На этом этапе используется Supervised Fine-Tuning (SFT) на качественных траекториях — примерах успешного решения задач.
Здесь команда использует два фреймворка:
- ReAct (Reasoning and Acting): Классический и всем известный формат "Мысль-Действие-Наблюдение". Он учит модель придерживаться строгой структуры рассуждений.
- IterResearch: Их собственная инновационная парадигма, о которой мы поговорим подробнее ниже. Траектории в этом формате учат модель долгосрочному планированию и синтезу информации.
Этот этап — как стажировка для модели, где она подсматривает за "экспертами" и учится их паттернам поведения.
Этап 3: Reinforcement Learning (RL) — Финальная шлифовка
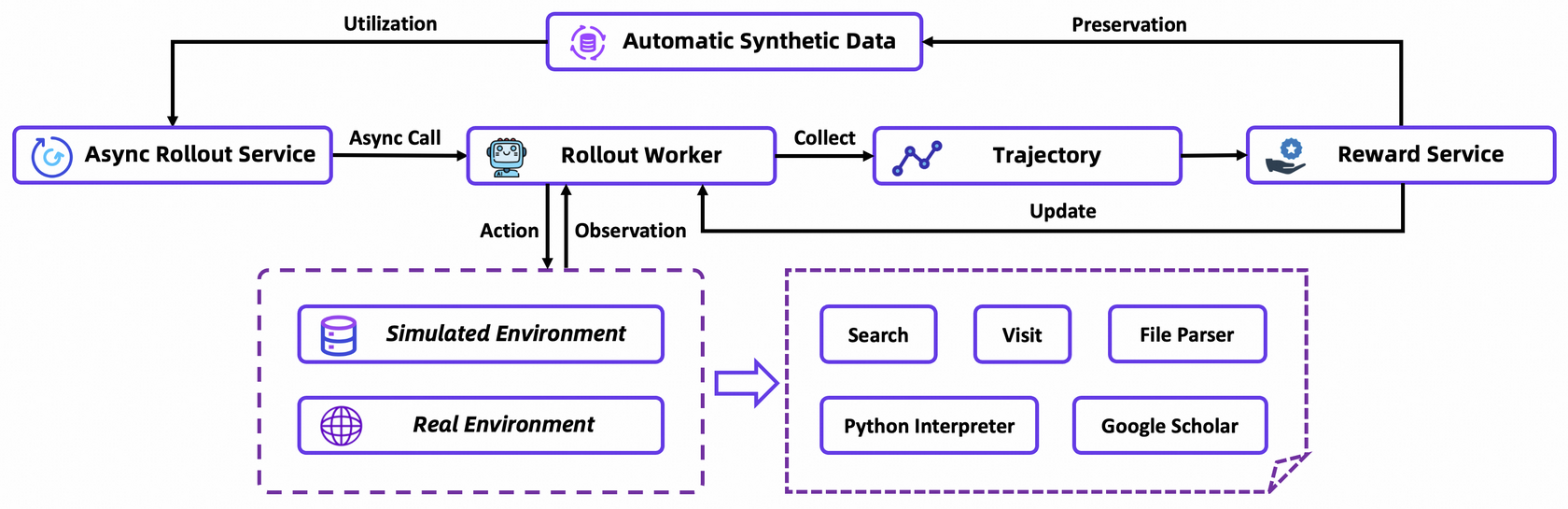
Последний и самый сложный этап — обучение с подкреплением. Здесь агент уже не просто копирует примеры, а самостоятельно пытается решать задачи, получая "награду" за правильные действия и "штраф" за неправильные.
Для этого используется кастомизированный on-policy алгоритм Group Relative Policy Optimization (GRPO). Ключевые моменты:
- On-policy обучение: Агент учится на данных, которые генерирует сам. Это гарантирует, что сигнал обучения всегда релевантен текущим возможностям модели.
- Стабильная среда: Обучение на "живом" вебе — это дорого, медленно и нестабильно. Поэтому команда создала симулированную среду на основе оффлайн-копии Википедии и кастомного набора инструментов. Это позволяет быстро и дешево итерироваться.
- Автоматическая курирование данных: Качество данных здесь важнее алгоритма. У них есть полностью автоматизированный пайплайн, который в реальном времени генерирует и фильтрует данные, подстраиваясь под динамику обучения модели.
Этот трехэтапный процесс позволяет превратить обычную LLM в высокоэффективного AI-исследователя. Но топливом для всего этого конвейера служат данные.
Синтетические данные: топливо для AI-исследователя
Команда Tongyi Lab прямо заявляет: "Данные — это основной драйвер улучшения возможностей модели; их важность даже превосходит важность алгоритма". И они построили машину для создания этих данных в промышленных масштабах.
Их подход эволюционировал:
WebWalker(ранний метод): Реверс-инжиниринг пар "вопрос-ответ" из логов кликов.WebSailor: Синтез данных на основе графов знаний.WebShaper: Формализация задачи информационного поиска на основе теории множеств.
Последний подход — самый интересный. Они научились программно контролировать сложность генерируемых вопросов. Это делается через "атомные операции" над графом знаний, например, слияние сущностей с похожими атрибутами, что намеренно запутывает вопрос и требует от агента более сложной цепочки рассуждений для поиска ответа.
[!TIP] Почему это так круто? Представьте, что вы можете сгенерировать датасет из миллиона вопросов уровня PhD, где каждый вопрос требует синтеза информации из 5-7 источников, проведения вычислений и глубокого анализа. Это позволяет "прокачивать" модель до сверхчеловеческих способностей в решении特定类型的 задач. Именно это они и сделали.
Теперь, когда мы понимаем, как модель обучается, давайте посмотрим, как она работает.
ReAct vs. IterResearch: Революция в мышлении агента
Обучение — это полдела. Не менее важно, как агент использует свои знания в момент выполнения задачи. И здесь Tongyi DeepResearch предлагает два режима работы ("rollout modes"), которые отражают эволюцию их подхода.
Классический подход: ReAct — простота и ее цена
Большинство современных агентов работают по парадигме ReAct (Reasoning and Acting). Это простой и понятный цикл:
- Thought (Мысль): Агент анализирует текущую ситуацию и планирует следующее действие.
- Action (Действие): Агент выполняет действие (например, делает поисковый запрос).
- Observation (Наблюдение): Агент получает результат действия (например, список ссылок) и добавляет его в свой контекст.
Этот цикл повторяется снова и снова. Весь диалог — мысли, действия, наблюдения — накапливается в одном постоянно растущем контекстном окне.
Плюс такого подхода — его универсальность. Он позволяет четко оценить "сырые" способности модели без сложного промпт-инжиниринга. И Tongyi DeepResearch отлично работает в этом режиме, что доказывает качество их пайплайна обучения.
Но у этого подхода есть огромная цена, особенно в долгих и сложных задачах.
[!DANGER] Проблемы ReAct: "Когнитивное удушье" и "шумовое загрязнение" Когда вся история взаимодействия сваливается в одну кучу, возникают две проблемы:
- Когнитивное удушье (Cognitive Suffocation): Контекстное окно забивается информацией. Важные детали, найденные в начале, "тонут" в массе более поздних, менее релевантных данных. Модели становится трудно удерживать фокус.
- Шумовое загрязнение (Noise Pollution): Неудачные поисковые запросы, тупиковые ветви рассуждений, ошибки — все это остается в контексте, загрязняя его и мешая принимать верные решения на более поздних этапах.
Это как пытаться написать диссертацию, постоянно дописывая новые мысли в один и тот же гигантский абзац. Рано или поздно вы потеряете нить повествования.
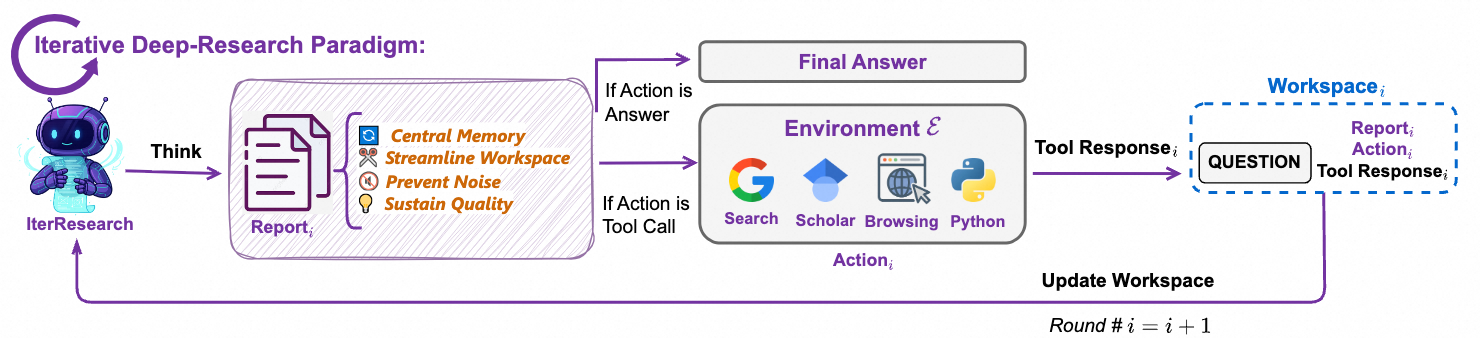
Новый подход: IterResearch — итеративное мышление и "чистый стол"
Чтобы решить эти проблемы, Tongyi Lab разработала собственную парадигму — IterResearch. Идея гениальна в своей простоте: вместо одного бесконечного мыслительного процесса, задача разбивается на серию "исследовательских раундов".
Вот как это работает:
- Начало раунда: Агент не тащит за собой весь предыдущий контекст. Вместо этого он создает новый, "чистый" воркспейс, в который помещает только самые важные выводы из предыдущего раунда.
- Работа в раунде: Внутри этого сфокусированного воркспейса агент анализирует подзадачу, находит новую информацию и интегрирует ключевые находки в постоянно обновляемый центральный отчет (central report).
- Завершение раунда: Агент решает, что делать дальше — либо перейти к следующему раунду для сбора дополнительной информации, либо, если данных достаточно, дать финальный ответ.
Этот итеративный процесс "синтеза и реконструкции" позволяет агенту поддерживать ясный "когнитивный фокус" на протяжении всей задачи.
[!TIP] Метафора "чистого стола" Представьте, что ReAct — это работа за столом, на который вы складываете все документы, книги и черновики, никогда ничего не убирая. Через час стол превратится в хаос. IterResearch — это работа, где в конце каждого часа вы убираете со стола все лишнее, оставляя только краткую сводку и план на следующий час. Это позволяет работать продуктивно бесконечно долго.
Более того, они развили эту идею до фреймворка Research-Synthesis, где несколько агентов-исследователей работают параллельно по парадигме IterResearch, а финальный агент-синтезатор объединяет их отчеты в один исчерпывающий ответ. Это позволяет исследовать больше путей за то же время.
Как это попробовать? Quick Start
Самое приятное — все это можно потрогать руками. Модель и код доступны на GitHub и HuggingFace. Вот пошаговая инструкция для запуска.
1. Настройка окружения
Рекомендуется использовать Python 3.10. Проще всего создать изолированное окружение через conda:
conda create -n deepresearch_env python=3.10.0
conda activate deepresearch_env
2. Установка зависимостей
pip install -r requirements.txt
3. Подготовка данных для оценки
- Создайте папку
eval_data/в корне проекта. - Поместите ваш файл с вопросами и ответами в формате
.jsonlвнутрь этой папки (например,eval_data/example.jsonl). - Каждая строка файла должна быть JSON-объектом с ключами
"question"и"answer".
{"question": "...", "answer": "..."}
[!NOTE] Если вы планируете использовать инструмент для парсинга файлов, имя файла нужно добавить в начало поля
"question", а сам файл положить вeval_data/file_corpus/.
4. Конфигурация скрипта
- Откройте скрипт
run_react_infer.sh. - Измените переменные, как указано в комментариях:
MODEL_PATH,DATASET,OUTPUT_PATH. - Пропишите необходимые API-ключи для инструментов, которые вы хотите использовать (например, для веб-поиска).
5. Запуск
bash run_react_infer.sh
Понравился материал?
Ваша поддержка — это энергия для новых статей и проектов. Спасибо, что читаете!
Ограничения и будущее: куда движется Alibaba
Команда честно признает текущие ограничения:
- Длина контекста: Даже 128к токенов все еще недостаточно для самых сложных и длинных задач.
- Масштабируемость: Их пайплайн обучения пока не проверен на моделях значительно крупнее 30B.
- Эффективность RL: Текущий on-policy RL-фреймворк довольно дорогой. Они планируют исследовать off-policy подходы для его удешевления.
Этот релиз — не единичный выстрел. Это кульминация целой серии работ (более 11 технических отчетов за последний год), посвященных созданию AI-агентов. Alibaba явно играет вдолгую, и их открытый подход к публикации методологий может серьезно ускорить развитие всего сообщества.
Так что же это значит для нас, разработчиков?
Теперь у сообщества есть не просто модель, а целый чертеж "завода" для их производства.
Это открывает огромные возможности:
- Для исследователей: Изучать, воспроизводить и улучшать передовые методы обучения агентов.
- Для стартапов и компаний: Создавать собственных узкоспециализированных AI-агентов для решения конкретных бизнес-задач, не начиная с нуля.
- Для энтузиастов: Экспериментировать с технологиями, которые еще вчера были доступны только гигантам индустрии.
Мир AI-агентов становится более открытым и конкурентным. И это, безусловно, хорошая новость для всех нас.