
Рынок больших языковых моделей напоминает гонку вооружений, где закрытые системы от гигантов вроде Google и OpenAI долгое время задавали темп. Но 22 сентября 2025 года команда QwenTeam (Alibaba) выпустили Qwen3-Omni — нативно омнимодальную модель с открытым исходным кодом, которая не просто "догоняет", а по ряду ключевых параметров превосходит таких монстров, как Gemini 2.5 Pro и GPT-4o.
Это не очередной рерайт LLaMA. Это принципиально новая архитектура и заявка на лидерство в open-source. В этой статье мы разберем, что у нее под капотом, на что она способна на практике, и как запустить ее у себя на машине.
Что такое Qwen3-Omni?
Если коротко, Qwen3-Omni — это модель, которая "из коробки" понимает и генерирует контент в разных модальностях: текст, изображения, аудио и видео. И ключевое слово здесь — "нативно". В отличие от многих "мультимодальных" систем, которые по сути являются склейкой нескольких специализированных моделей, Qwen3-Omni обучалась одновременно на всех типах данных. Это позволяет ей не терять в качестве при работе с одной модальностью и при этом показывать высокие результаты в кросс-модальных задачах.
Ключевые особенности, которые заставляют напрячься конкурентов:
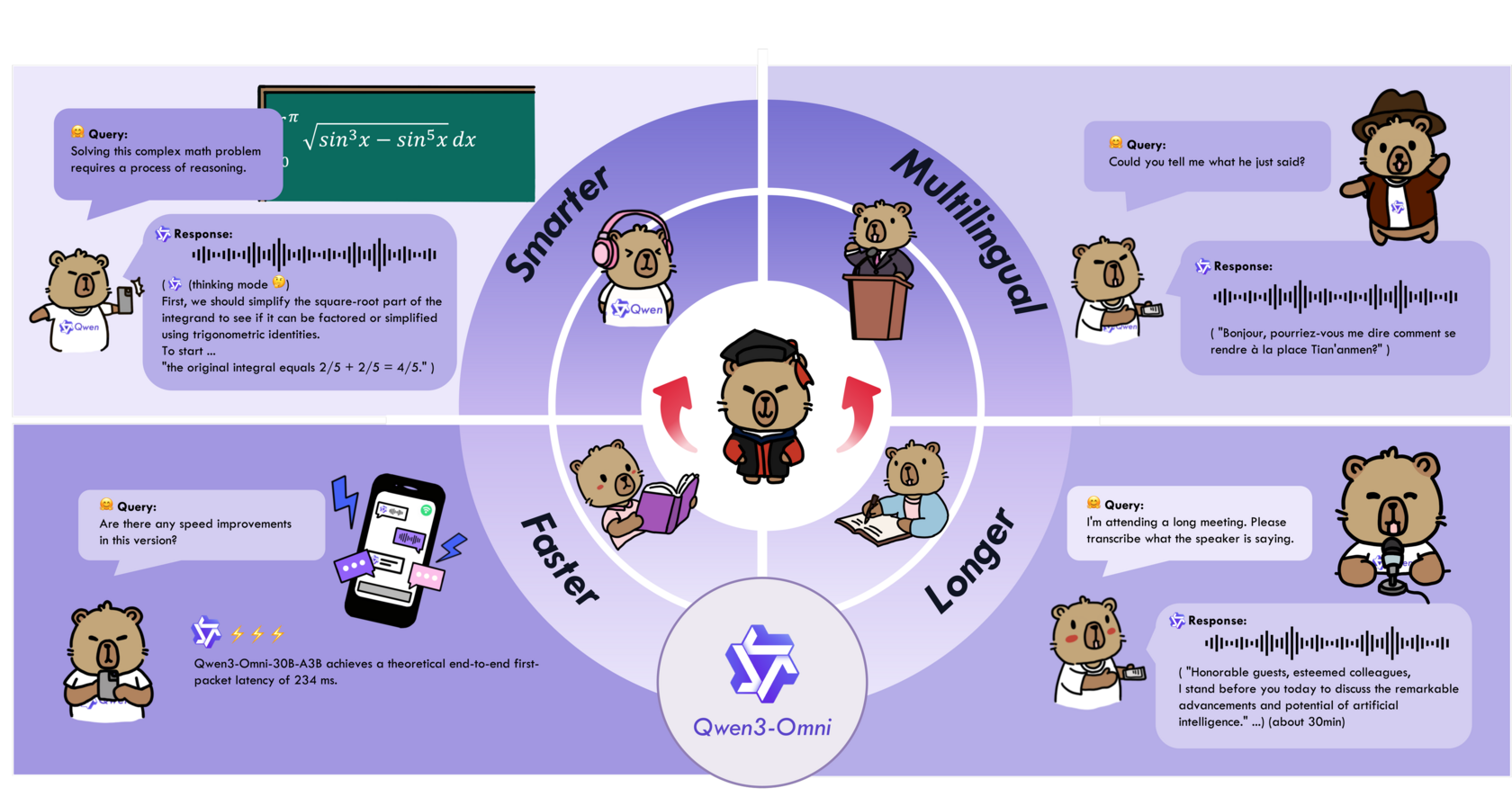
- 🏆 Производительность уровня SOTA: Модель занимает первое место на 32 из 36 аудио- и аудиовизуальных бенчмарков, обгоняя закрытые аналоги вроде
Gemini-2.5-Pro,Seed-ASRиGPT-4o-Transcribe. - 🗣️ Истинная многоязычность: Поддерживает текстовое взаимодействие на 119 языках, понимание речи на 19 и генерацию речи на 10 языках.
- ⚡ Сверхнизкая задержка: Ответ в аудио-сценариях всего за 211 мс, в аудио-видео — 507 мс. Это позволяет создавать голосовых ассистентов, работающих в реальном времени.
- 👂 Длинный слух: Способна обрабатывать аудиозаписи длиной до 30 минут.
- 🔧 Гибкая настройка и Tool Calling: Легко адаптируется через системные промпты и поддерживает вызов внешних функций, что открывает дорогу для интеграции с любыми сервисами.
- 📜 Открытая лицензия Apache 2.0: Модель можно свободно использовать, модифицировать и применять в коммерческих продуктах. Это, пожалуй, главный удар по закрытым экосистемам.
По сути, QwenTeam выложили в открытый доступ инструмент, по мощности сопоставимый с последними разработками техногигантов. Для разработчиков и бизнеса это означает одно: возможность создавать продукты нового поколения без необходимости платить за API и зависеть от прихотей корпораций.
Под капотом: Архитектура Thinker-Talker
Самое интересное в Qwen3-Omni — это ее архитектура. Вместо монолитного подхода разработчики использовали элегантное решение под названием Thinker-Talker ("Мыслитель-Говорун").
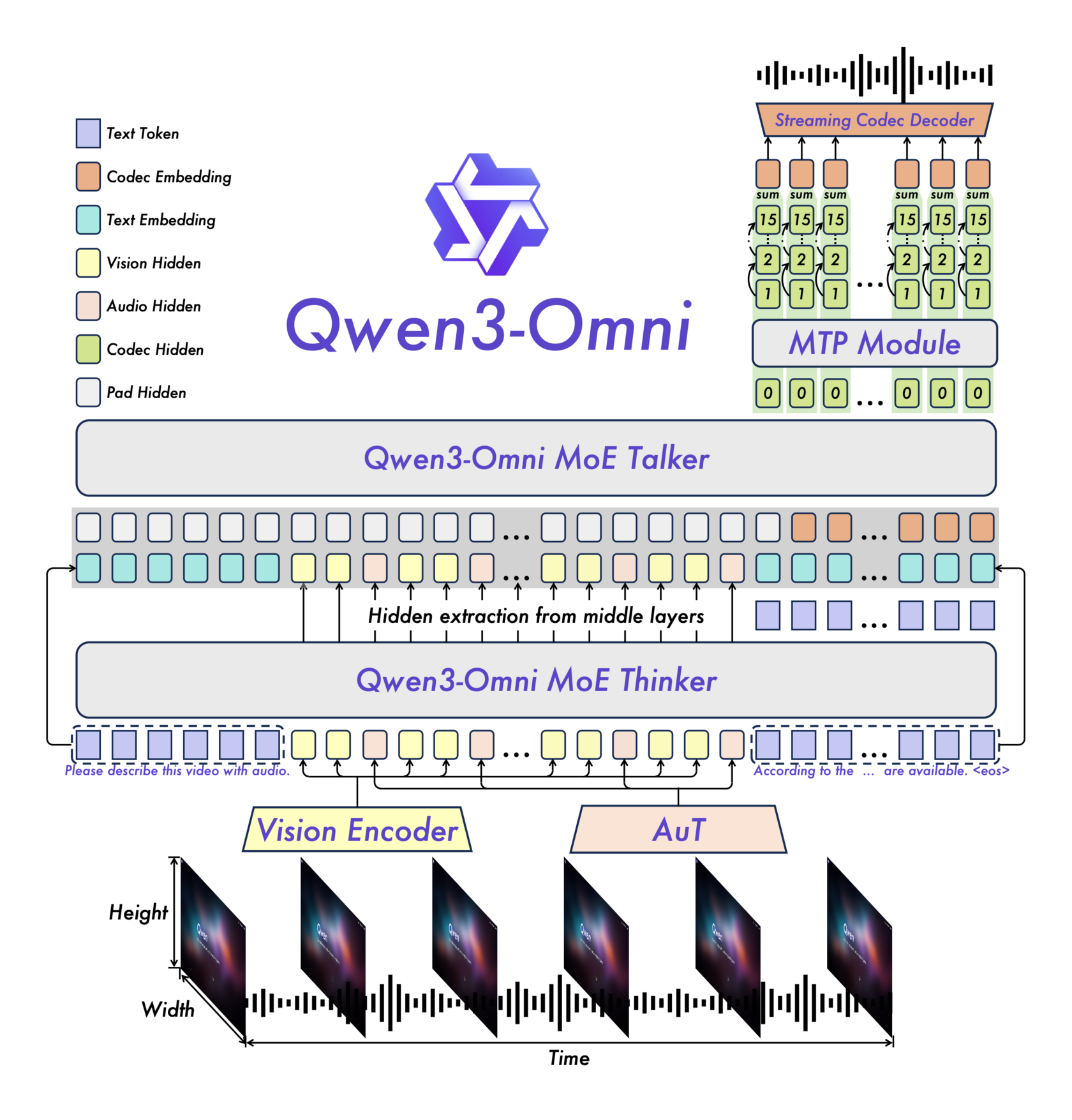
Эта архитектура разделяет процесс генерации ответа на две логические части, что позволяет достичь и высокой производительности, и низкой задержки.
Мыслитель (Thinker)
Thinker — это ядро модели, отвечающее за генерацию текста и высокоуровневое понимание. Именно он анализирует входящие данные (текст, картинки, аудиодорожки) и формирует семантически богатый, но еще не озвученный "план" ответа.
Для повышения эффективности и скорости работы Thinker использует архитектуру Mixture-of-Experts (MoE). Вместо того чтобы при каждом запросе задействовать всю гигантскую нейросеть, MoE активирует только небольшую часть "экспертов" — специализированных подсетей, наиболее релевантных для данной задачи. Это как если бы для ответа на вопрос по физике вы обращались не ко всей библиотеке, а только к полке с учебниками по физике. Результат — значительное ускорение инференса и возможность обрабатывать больше параллельных запросов.
Говорун (Talker)
Talker получает высокоуровневые представления от Thinker и его задача — преобразовать их в поток токенов речи. Именно он отвечает за генерацию естественного голоса в режиме реального времени.
Чтобы добиться стриминга с минимальной задержкой, Talker использует несколько ключевых технологий:
- Авторегрессионная генерация: Он предсказывает аудио-токены последовательно, один за другим.
- Multi-Codebook: Вместо одного "кодека" используется несколько, что позволяет генерировать аудио "кадр" за один шаг.
- Code2Wav рендерер: Специальный модуль, который инкрементально, кадр за кадром, синтезирует финальную звуковую волну.
[!INFO] Такая связка позволяет начать воспроизведение аудио почти мгновенно, как только
Thinkerсформировал первую часть мысли. Пользователь слышит начало ответа, пока модель продолжает генерировать его окончание. Это и создает ощущение живого диалога.
Другие важные компоненты
- AuT (Audio Transformer): Мощный энкодер для аудио, предобученный на 20 миллионах часов аудиоданных. Именно он обеспечивает глубокое понимание звука.
- Отсутствие деградации: Благодаря совместному обучению на всех модальностях с самого раннего этапа, Qwen3-Omni одинаково хорошо справляется с задачами в рамках одной модальности (например, только текст или только аудио) и со сложными кросс-модальными запросами.
Производительность в цифрах: Сравнение с гигантами
Заявления о "превосходстве" — это стандартный маркетинговый ход. Но в случае Qwen3-Omni они подкреплены результатами на общепринятых бенчмарках. Команда провела всестороннее тестирование, и результаты говорят сами за себя.
[!NOTE] Бенчмарк — это стандартизированный набор тестов для оценки производительности системы. Результаты на бенчмарках позволяют объективно сравнивать разные модели.
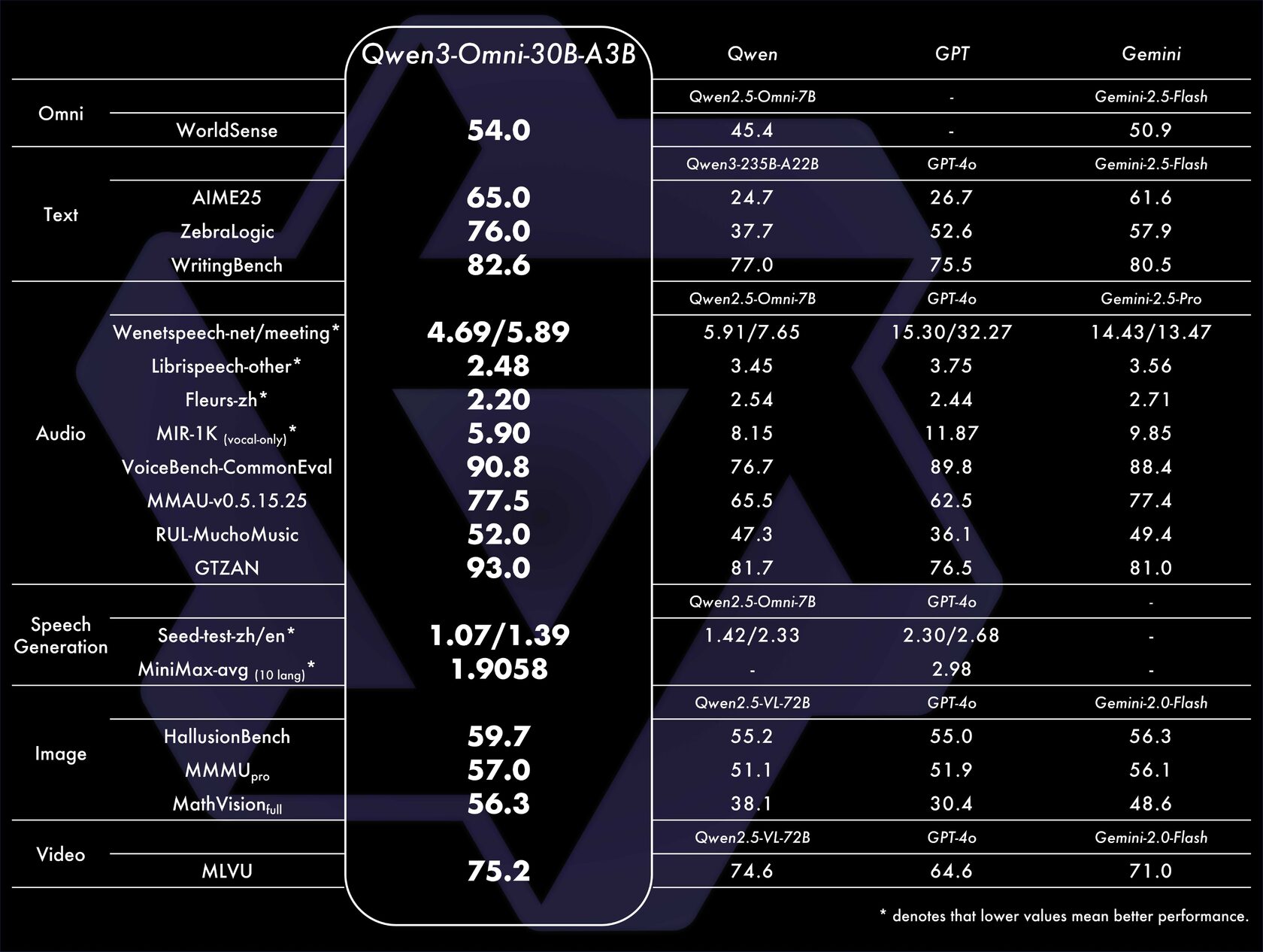
Особенно впечатляют результаты в задачах, связанных со звуком. Модель не просто транскрибирует речь, а глубоко понимает аудиоконтекст, что открывает двери для создания умных ассистентов, систем анализа звонков и инструментов для людей с нарушениями слуха.
Запускаем Qwen3-Omni: пошаговое руководство
Теория — это хорошо, но настоящая магия начинается, когда ты можешь запустить модель сам. Разберем, как поднять Qwen3-Omni локально.
Варианты инференса: Transformers vs. vLLM
Для запуска модели можно использовать две основные библиотеки:
- Hugging Face Transformers: Стандарт де-факто для работы с трансформерными моделями. Проще в настройке, идеально для экспериментов и задач, где не требуется максимальная пропускная способность. Важно: на данный момент, генерация аудио поддерживается только через
transformers. - vLLM: Высокооптимизированный движок для инференса LLM. Обеспечивает значительно более высокую скорость и пропускную способность за счет техник вроде PagedAttention. Идеален для продакшена и высоконагруженных сервисов. Аудио-генерацию пока не поддерживает.
Выбор зависит от вашей задачи. Для "поиграться" и оценить все фичи — берите transformers. Для развертывания сервиса — vLLM.
Установка и настройка окружения
Предполагается, что у вас установлены Python 3.10+, CUDA и соответствующие драйверы NVIDIA.
# Устанавливаем основные зависимости
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu121
# Устанавливаем Transformers из git для поддержки Qwen3-Omni
pip install git+https://github.com/huggingface/transformers
# Для максимальной производительности ставим flash-attn
# Убедитесь, что ваша карта его поддерживает (Ampere или новее)
pip install flash-attn --no-build-isolation
# Устанавливаем специфичные для модели утилиты и зависимости
pip install accelerate qwen-omni-utils soundfile librosa av
# Если планируете использовать vLLM
# pip install vllm
[!WARNING] Установка
flash-attnможет быть капризной. Внимательно читайте логи и при необходимости обратитесь к официальной документацииflash-attnдля решения проблем со сборкой.
Пример 1: Описываем видео без звука
Давайте попросим модель описать, что происходит в коротком видеоролике. Этот пример показывает ее способность к визуальному анализу. Мы намеренно отключим обработку аудиодорожки (use_audio_in_video=False), чтобы оценить именно "зрение" модели.
import torch
from transformers import Qwen3OmniMoeForConditionalGeneration, Qwen3OmniMoeProcessor
from qwen_omni_utils import process_mm_info
# Указываем путь к модели (скачается автоматически) и выбираем устройство
MODEL_PATH = "Qwen/Qwen3-Omni-30B-A3B-Instruct"
device = "cuda" if torch.cuda.is_available() else "cpu"
# Загружаем модель и процессор
# attn_implementation="flash_attention_2" для ускорения на совместимых GPU
model = Qwen3OmniMoeForConditionalGeneration.from_pretrained(
MODEL_PATH,
dtype='auto',
attn_implementation='flash_attention_2',
device_map="auto"
)
processor = Qwen3OmniMoeProcessor.from_pretrained(MODEL_PATH)
# --- Наш запрос ---
video_path = "https://qianwen-res.oss-cn-beijing.aliyuncs.com/Qwen3-Omni/cookbook/video1.mp4"
prompt = "Describe the video in detail."
messages = [
{
"role": "user",
"content": [
{"type": "video", "video": video_path},
{"type": "text", "text": prompt}
]
}
]
# --- Обработка и генерация ---
# Готовим входные данные для модели
text = processor.apply_chat_template(messages, add_generation_prompt=True, tokenize=False)
# Извлекаем медиа-данные, звук из видео игнорируем
audios, images, videos = process_mm_info(messages, use_audio_in_video=False)
inputs = processor(
text=text,
audio=audios,
images=images,
videos=videos,
return_tensors="pt",
padding=True,
use_audio_in_video=False
)
inputs = inputs.to(model.device).to(model.dtype)
# Генерируем ответ
# thinker_max_new_tokens - максимальная длина ответа
text_ids, _ = model.generate(
**inputs,
thinker_return_dict_in_generate=True,
thinker_max_new_tokens=2048,
thinker_do_sample=False, # Используем детерминированную генерацию
use_audio_in_video=False,
return_audio=False # Аудио-ответ нам не нужен
)
response = processor.batch_decode(
text_ids.sequences[:, inputs["input_ids"].shape[1]:],
skip_special_tokens=True
)[0]
print(response)
# Примерный вывод:
# The video showcases a series of impressive acrobatic performances by various gymnasts...
# ...demonstrating the athletes' skill and artistry.
Этот скрипт скачает модель (будьте готовы, она весит десятки гигабайт), обработает видео по URL и выдаст его текстовое описание.
Пример 2: Аудио-визуальный диалог
Теперь усложним задачу. Дадим модели видео со звуком и зададим вопрос, ответ на который требует одновременного анализа и картинки, и речи персонажей.
# ... (код загрузки модели и процессора тот же, что и в Примере 1) ...
# --- Наш запрос ---
video_path = "https://qianwen-res.oss-cn-beijing.aliyuncs.com/Qwen3-Omni/cookbook/audio_visual.mp4"
prompt = "What was the first sentence the boy said when he met the girl?"
messages = [
{
"role": "user",
"content": [
{"type": "video", "video": video_path},
{"type": "text", "text": prompt}
]
}
]
# --- Обработка и генерация ---
# Теперь use_audio_in_video=True
text = processor.apply_chat_template(messages, add_generation_prompt=True, tokenize=False)
audios, images, videos = process_mm_info(messages, use_audio_in_video=True)
inputs = processor(
text=text, audio=audios, images=images, videos=videos,
return_tensors="pt", padding=True, use_audio_in_video=True
)
inputs = inputs.to(model.device).to(model.dtype)
text_ids, audio_response = model.generate(
**inputs,
thinker_return_dict_in_generate=True,
thinker_max_new_tokens=2048,
thinker_do_sample=False,
speaker="Ethan", # Можно выбрать один из голосов
use_audio_in_video=True,
return_audio=True # Запрашиваем аудио-ответ
)
response_text = processor.batch_decode(
text_ids.sequences[:, inputs["input_ids"].shape[1]:],
skip_special_tokens=True
)[0]
print("Текстовый ответ:", response_text)
# Сохраняем аудио-ответ в файл
if audio_response is not None:
import soundfile as sf
import numpy as np
audio_np = np.array(audio_response.reshape(-1).float().cpu().numpy() * 32767).astype(np.int16)
sf.write("response.wav", audio_np, samplerate=24000)
print("Аудио-ответ сохранен в response.wav")
# Вывод:
# Текстовый ответ: Hey, it's cold out here.
# Аудио-ответ сохранен в response.wav
Здесь модель не просто "увидела" мальчика и девочку, но и "услышала" и расшифровала его первую реплику. Более того, она сгенерировала не только текстовый, но и голосовой ответ, который мы сохранили в .wav файл.
Локальное демо с Gradio
Для тех, кто предпочитает интерактивное взаимодействие, команда подготовила готовые демо-приложения на Gradio. Вы можете запустить их локально и общаться с моделью через веб-интерфейс, загружая свои аудио, видео и изображения.
Для запуска основного демо, склонируйте репозиторий проекта и выполните:
# Клонируем репозиторий
git clone https://github.com/QwenLM/Qwen3-Omni.git
cd Qwen3-Omni
# Запускаем веб-демо
python web_demo.py --checkpoint-path Qwen/Qwen3-Omni-30B-A3B-Instruct --use-transformers --generate-audio --flash-attn2
После запуска в терминале появится ссылка (обычно http://127.0.0.1:8901), которую можно открыть в браузере.
Понравился материал?
Ваша поддержка — это энергия для новых статей и проектов. Спасибо, что читаете!
Для кого эта модель?
Qwen3-Omni — это мощный, универсальный и, что самое главное, открытый инструмент.
- Для разработчиков и стартапов: Это возможность создавать продукты с омнимодальными возможностями, которые раньше были доступны только корпорациям с миллиардными бюджетами. Голосовые ассистенты нового поколения, системы видеоаналитики, инструменты для творчества — все это теперь можно строить на базе open-source.
- Для исследователей: Это мощнейшая платформа для экспериментов в области мультимодального ИИ, не обремененная ограничениями закрытых API.
- Для бизнеса: Это шанс интегрировать передовые ИИ-технологии в свои процессы, не попадая в зависимость от одного поставщика и его ценовой политики.
Открытые модели могут не просто конкурировать с закрытыми аналогами, но и превосходить их. Гонка продолжается, и от этого выигрываем мы все.