Все, кто хоть раз пытался склеить воедино сложный AI-проект на Python, особенно если там замешаны мультимодальные данные и требования к реальному времени, знают эту боль. Это не разработка, а сборка пазла из горящих кусков: тут тебе и асинхронные вызовы API, и обработка потоковых данных, и кастомная логика, которую надо как-то подружить друг с другом. В итоге получается что-то, что работает, но скрипит, падает и заставляет тебя мечтать о кнопке "отменить все изменения за последние три дня".
И тут Google DeepMind выкатывает свой genai-processors. С первого взгляда может показаться, что это просто очередная библиотека для работы с LLM. Но копая глубже, понимаешь: это не просто библиотека, а целый фреймворк, который предлагает принципиально новый подход к организации AI-приложений. Можно сказать, это как появление Git для контроля версий или Docker для развертывания — новый уровень стандартизации и структуры там, где раньше царил хаос.
💡 Что такое GenAI Processors и почему это другое?
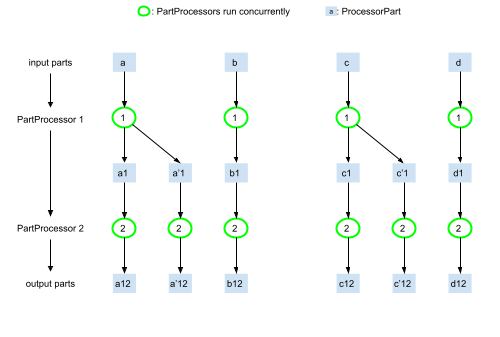
В основе genai-processors лежит простая, но мощная идея: всё — это потоки ProcessorPart'ов. Не просто функции, которые что-то принимают и что-то возвращают, а целые "процессоры", которые берут один асинхронный поток данных и возвращают другой.
ProcessorPart: Атомарная единица данных
Представьте, что ваше AI-приложение работает с кучей всего: вот аудио-отрывок, вот его текстовая транскрипция, а вот кадр видео, а тут вообще какой-то кастомный JSON. Традиционно, каждый такой кусочек приходилось бы обрабатывать по-своему. ProcessorPart унифицирует этот хаос. Это такая типовая обёртка для любого типа данных — будь то текст, изображение, аудио или что угодно другое. Каждый ProcessorPart несёт в себе сам контент, его MIME-тип и, что важно, метаданные.
[!INFO] Важные метаданные
ProcessorPart
mimetype: тип контента (например,text/plain,image/png,audio/wav).role: кто произвел контент (например,user,model,tool).substream_name: позволяет разделить поток на логические "подпотоки" для разных целей (например,realtimeдля Live API,statusдля отладки).metadata: произвольный словарь для любых дополнительных данных.
Processor и PartProcessor: Движки конвейера
Имея ProcessorPart как атомарную единицу, genai-processors вводит два ключевых понятия для работы с ними:
Processor: Это основной строительный блок. Он принимает на входAsyncIterable[ProcessorPart](то есть поток!) и возвращаетAsyncIterable[ProcessorPart]. Проще говоря, это функция, которая постоянно работает с данными, протекающими через неё. ВнутриProcessorможет буферизовать данные, обрабатывать их последовательно, принимать решения, основываясь на всем потоке.PartProcessor: Это более специализированный типProcessor, который обрабатывает каждый отдельныйProcessorPartнезависимо и конкурентно. Если вам не важен порядок обработки частей друг относительно друга,PartProcessor— ваш выбор. Он позволяет достичь максимальной эффективности за счет параллелизма: пока одинPartProcessorобрабатывает кадр видео, другой уже занимается текстовой транскрипцией.
[!TIP] Зачем так сложно?
PartProcessorы — это та самая магия, которая позволяет библиотеке обещать низкий Time-To-First-Token (TTFT) и высокую отзывчивость. Когда вы объединяетеPartProcessorы в цепочки, они работают как конвейер, где каждый этап запускается, как только предыдущий отдал ему часть работы, не дожидаясь завершения всей задачи.
Цепочки и параллельные ветки: Операторы + и //
Одна из самых крутых фич genai-processors — это интуитивный синтаксис для композиции. Вы можете:
- Объединять процессоры в цепочки оператором
+:processor1 + processor2 + processor3. Выход одного становится входом для следующего. Это классический конвейер. - Запускать
PartProcessorы параллельно оператором//:part_processor1 // part_processor2. Оба процессора получают на вход одни и те же данные, и их выходные потоки объединяются. Это идеально для обработки одного и того же входного сигнала разными способами одновременно (например, один анализирует изображение, другой — звук).
[!NOTE] Автоматическая оптимизация Библиотека сама определяет, когда можно запустить параллельные вычисления, даже если вы просто используете оператор
+. Она умеет преобразовывать цепочкиPartProcessorов в эффективные параллельные графы выполнения.
🏗️ Скелет AI-агента: Код, который не стыдно показать
Чтобы не быть голословным, давайте посмотрим на примеры архитектур, которые предлагает genai-processors.
От микрофона до ответа: Live Agent в действии
Представьте себе AI-агента, который слушает и видит вас в реальном времени, а затем отвечает голосом. Такое обычно строят на каких-то фреймворках для видеоконференций или специализированных API. С genai-processors это выглядит так (сильно упрощенный, но рабочий пример):
from genai_processors.core import audio_io, live_model, video
from genai_processors import streams
# Входной процессор: объединяет потоки с камеры и аудио с микрофона
input_processor = video.VideoIn() + audio_io.PyAudioIn(...)
# Выходной процессор: воспроизводит аудио. Обрабатывает прерывания и паузы,
# когда пользователь говорит.
play_output = audio_io.PyAudioOut(...)
# Процессор для взаимодействия с Gemini Live API
live_processor = live_model.LiveProcessor(
api_key='YOUR_API_KEY',
model_name='gemini-2.0-flash-live-001',
# ... тут ещё куча настроек для Live API, инструментов и т.д.
)
ато
# Компонуем агента: микрофон+камера -> Gemini Live API -> воспроизведение аудио
live_agent = input_processor + live_processor + play_output
async for part in live_agent(streams.endless_stream()):
# Обрабатываем выходные данные (например, печатаем транскрипцию, выход модели, метаданные)
print(part)
Магия здесь в том, что video.VideoIn() и audio_io.PyAudioIn() — это "источники" (@processor.source), которые сами начинают генерировать ProcessorPartы (кадры видео, аудио-чанки). live_processor получает их, отправляет в Gemini Live API, а затем play_output воспроизводит ответ. Чисто, красиво, и каждый компонент можно переиспользовать или заменить.
Когда Live API не нужен: Real-time агент на чистом Python
А что, если нам не нужен именно Live API, а хочется собрать что-то подобное на обычном текстовом LLM, но с поддержкой аудио? Тоже не проблема:
from genai_processors.core import (
audio_io,
genai_model,
rate_limit_audio,
realtime,
speech_to_text,
text_to_speech,
)
# Входной процессор: берёт аудио с микрофона и транскрибирует в текст
input_processor = audio_io.PyAudioIn(...) + speech_to_text.SpeechToText(...)
play_output = audio_io.PyAudioOut(...)
# Основная модель, которая будет генерировать ответ (например, Gemini Flash)
genai_processor = genai_model.GenaiModel(api_key='YOUR_API_KEY', model_name='gemini-2.0-flash-lite')
# TTS-процессор, который преобразует текстовый ответ в аудио.
# rate_limit_audio нужен, чтобы плавно стримить аудио и
# управлять прерываниями, если пользователь начнет говорить.
tts = text_to_speech.TextToSpeech(...) + rate_limit_audio.RateLimitAudio(...)
# Создаем агента:
# микрофон -> речь в текст -> текстовая беседа -> текст в речь -> воспроизведение аудио
live_agent = (
input_processor
+ realtime.LiveModelProcessor(turn_processor=genai_processor + tts)
+ play_output
)
# ... асинхронный цикл обработки
Тут realtime.LiveModelProcessor — это тот самый умный обёртчик, который превращает обычную "тумблерную" модель (запрос-ответ) в полноценный двунаправленный стриминговый интерфейс. Он сам управляет историей промптов, прерываниями и триггерами ответов, избавляя вас от низкоуровневой логики.
Агенты-исследователи и планировщики путешествий: гибкость в каждой строчке
Помимо real-time сценариев, genai-processors отлично справляется и с более классическими "пошаговыми" агентами. В репозитории есть примеры:
- Research Agent: Агент, который получает запрос, сам декомпозирует его на темы для исследования, ищет информацию с помощью инструментов (например, Google Search API, через
drive.Docsилиdrive.Sheetsдля документов) и синтезирует финальный ответ. ЗдесьPartProcessorы используются, чтобы параллельно исследовать несколько тем. - Trip Planner: Планировщик путешествий, который сначала быстро валидирует запрос пользователя (используя легкую модель), а затем, пока пользователь получает подтверждение, в фоне строит детализированный план поездки (используя более мощную модель). Это отличный пример того, как
genai-processorsпомогает снизить "воспринимаемую задержку" (perceived latency) за счет грамотного параллелизма.
⚙️ Под капотом: Ключевые принципы архитектуры
Что делает genai-processors таким гибким и мощным? Несколько фундаментальных дизайн-принципов:
- Модульный дизайн: Всё разбито на самодостаточные
Processorы. Это не просто удобно; это делает код более тестируемым, переиспользуемым и, самое главное, гораздо проще в поддержке. Прощай, километровые скрипты! - Асинхронность и конкурентность: Библиотека на полную катушку использует
asyncioPython'а. Это позволяет ей эффективно жонглировать I/O-операциями (сетевые запросы к API) и вычислительно-тяжелыми задачами (обработка данных), обеспечивая высокую отзывчивость без необходимости вручную писать сложный многопоточный код. - Интеграция с Gemini API: Есть готовые обёртки для всех типов взаимодействия с Gemini:
GenaiModelдля обычных запросов иLiveProcessorдля реального времени. Это сильно сокращает бойлерплейт-код. - Расширяемость: Вы можете легко создавать свои кастомные процессоры, наследуясь от базовых классов или используя простые декораторы. Это позволяет вам встраивать любую свою логику, сторонние API или специфические операции.
- Единая обработка мультимодальных данных:
ProcessorPartдействительно решает проблему работы с разнородными данными. Не нужно каждый раз писать парсеры для каждого типа контента; всё унифицировано. - Утилиты для манипуляции потоками: Функции для разделения, конкатенации и объединения асинхронных потоков дают вам полный контроль над тем, как данные текут по вашему приложению.
🤔 А что по минусам?
Конечно, идеальных инструментов не бывает, и genai-processors — не исключение.
- Python-only: Пока библиотека доступна только для Python. Это логично, учитывая её глубокую интеграцию с
asyncioи экосистемой ML, но ограничивает кросс-платформенное использование. - Кривая обучения: Хотя авторы говорят о "простоте", работа с асинхронными потоками,
ProcessorPart'ами, а тем более с глубокими особенностямиasyncio, всё ещё может быть сложной для новичков. Не ждите, что вы "сразу начнели" клепать агентов, если до этого не работали сasync/await. - Ранняя стадия: Библиотека только-только вышла. Это значит, что API могут меняться, баги будут находиться, и комьюнити только начинает формироваться. Пока не ясно, насколько активно будет развиваться сообщество в
contrib/, и не станет ли это ещё одной "крутой штукой от Google", которую потом забросят.
🚀 Так что, стоит ли лезть?
Однозначно да, если вы:
- Python-разработчик, который плотно работает с LLM или планирует это делать.
- Строите сложные AI-агенты, где важна отзывчивость, мультимодальность и масштабируемость.
- Устали от хаоса в своих AI-скриптах и ищете чистую, модульную архитектуру.
genai-processors — это инструмент, который позволяет думать о потоках данных, а не о низкоуровневых деталях конкурентности.
Что думаете?
Поделитесь своими мыслями в комментариях! Уже пробовали genai-processors? Или есть другие фреймворки, которые вам нравятся больше?
Понравился разбор? Поддержите проект донатом — это мотивирует делать еще больше качественного контента!
Обсудить эту статью и другие новости Python/AI в нашем Telegram-канале: @pythontalk_ru
Более краткая версия для тех, кто спешит, есть на Дзене.