Исследование и подготовка данных — это фундамент, на котором строятся любые проекты в Data Science. Новички часто привыкают к "стерильным" учебным датасетам, где все гладко и чисто. Реальность же больше похожа на археологические раскопки: данные почти всегда неполные, с ошибками, неточностями и, конечно, пропусками.
Пропуски появляются по тысяче причин: сломался датчик, оператор поленился внести данные, произошел сбой при передаче, или в старой базе просто не было такого поля. Игнорировать их нельзя: большинство алгоритмов машинного обучения с пропусками не работают.
В зависимости от источника данных пропуски могут иметь разные обозначения. Наиболее часто используется NaN (Not a Number), но также можно встретить «NA», «None», «-999», «0», « », «-», «?» и другие варианты.
Если в датафрейме отсутствуют данные и они обозначены не как NaN, то их необходимо преобразовать в NaN. Например, можно использовать следующий код:
df = df.replace('', np.nan)
Первая реакция любого, кто работает с Pandas, — вызвать df.isna().sum(). Мы получаем аккуратную табличку с количеством пропусков по каждому столбцу и чувствуем, что контролируем ситуацию. Но это иллюзия. Знать сколько данных пропущено — это лишь первый шаг. Гораздо важнее понять, как они пропущены. Есть ли в этих пропусках система? Связаны ли они между собой? Являются ли они случайным шумом или сигналом о серьезных проблемах в данных?
Простой подсчет NaN не ответит на эти вопросы. Чтобы перейти от поверхностного взгляда к глубокому пониманию, нам нужен специализированный инструмент. И здесь на сцену выходит missingno.
Почему стандартных средств Pandas недостаточно?
Pandas — очень хороший инструмент. И для первичной оценки пропусков у него есть всё необходимое. Прежде чем мы погрузимся в missingno, быстро вспомним арсенал Pandas, чтобы понять его границы.
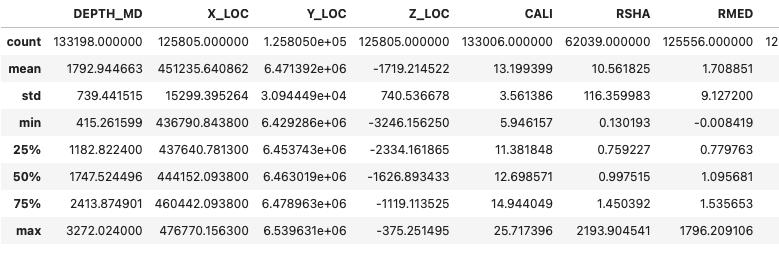
Возьмем для примера датасет с данными каротажа по скважинам в Норвежском море. Они содержат серию электрических измерений, которые были получены с помощью инструментов для каротажа скважин. Измерения используются для характеристики геологии недр и определения подходящих залежей углеводородов. Это реальные данные, а значит, они неидеальны.
import pandas as pd
import numpy as np
# Загружаем данные
df = pd.read_csv('https://github.com/obulygin/content/raw/refs/heads/main/xeek_data/xeek_train_subset.csv')
df
1. Метод .info()
Это наш первый взгляд на здоровье датафрейма.
df.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 133198 entries, 0 to 133197
Data columns (total 22 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 WELL 133198 non-null object
1 DEPTH_MD 133198 non-null float64
2 X_LOC 125805 non-null float64
3 Y_LOC 125805 non-null float64
4 Z_LOC 125805 non-null float64
5 GROUP 133198 non-null object
6 FORMATION 111632 non-null object
7 CALI 133006 non-null float64
8 RSHA 62039 non-null float64
9 RMED 125556 non-null float64
10 RDEP 125805 non-null float64
11 RHOB 108053 non-null float64
12 GR 133198 non-null float64
13 NPHI 91725 non-null float64
14 PEF 100840 non-null float64
15 DTC 132635 non-null float64
16 SP 93680 non-null float64
17 ROP 130454 non-null float64
18 DTS 12184 non-null float64
19 DCAL 56200 non-null float64
20 DRHO 105539 non-null float64
21 LITHOFACIES 133198 non-null int64
dtypes: float64(18), int64(1), object(3)
memory usage: 22.4+ MB
Вывод .info() уже дает нам важную подсказку. Общее число записей (RangeIndex) — 133,198. Но Non-Null Count у многих столбцов (X_LOC, FORMATION, CALI и т.д.) заметно меньше. Это прямое указание на наличие пропусков.
2. Метод .isna().sum()
Самый прямой способ подсчитать пропуски:
df.isna().sum()
WELL 0
DEPTH_MD 0
X_LOC 7393
Y_LOC 7393
Z_LOC 7393
GROUP 0
FORMATION 21566
CALI 192
RSHA 71159
RMED 7642
RDEP 7393
RHOB 25145
GR 0
NPHI 41473
PEF 32358
DTC 563
SP 39518
ROP 2744
DTS 121014
DCAL 76998
DRHO 27659
LITHOFACIES 0
dtype: int64
Метод isna() возвращает логический массив с True (если значение является пропуском) и False - если нет. А sum() суммирует элементы в этом массиве (где True будут единицами, а False — нулями), так мы и получим количество пропусков. Теперь у нас есть точные цифры. Мы видим, что в некоторых столбцах (X_LOC, Y_LOC, Z_LOC, RDEP) одинаковое количество пропусков — 7393. Это уже наводит на мысль о неслучайности. Столбец DTS пропущен более чем в ста тысячх строк — он почти пустой. DCAL, RSHA тоже выглядят плохо.
В чем же проблема?
Мы знаем что и сколько. Но мы не видим картину целиком.
- Где именно в датафрейме расположены эти пропуски? В начале, в конце, равномерно?
- Если в строке пропущено значение
X_LOC, пропущено ли там иY_LOC? (Судя по одинаковому числу — да, но это лишь гипотеза). - Связаны ли пропуски в
RHOBс пропусками вCALI? - Являются ли пропуски в
DTSсвойством определенных скважин или они случайны?
Ответы на эти и другие вопросы определяют стратегию работы с данными. Простое удаление строк (dropna()) может уничтожить ценную информацию, а наивная замена средним — исказить распределение и связи между признаками.
Нам нужен инструмент, который превратит эту сухую таблицу чисел в наглядную карту. И этот инструмент — missingno.
Визуальный аудит с missingno: от графиков к инсайтам
missingno — это не просто библиотека для красивых графиков. Это философия визуального аудита данных. Она предоставляет четыре мощных инструмента, каждый из которых отвечает на свой класс вопросов о структуре пропусков.
Установка стандартная:
pip install missingno
А теперь давайте проведем настоящее расследование, используя наш датасет.
msno.bar(): Быстрая оценка полноты
Столбчатая диаграмма — это аналог isna().sum(), но в графическом виде. Она показывает, какая доля данных присутствует в каждом столбце.
import missingno as msno
import matplotlib.pyplot as plt
msno.bar(df)
plt.show()
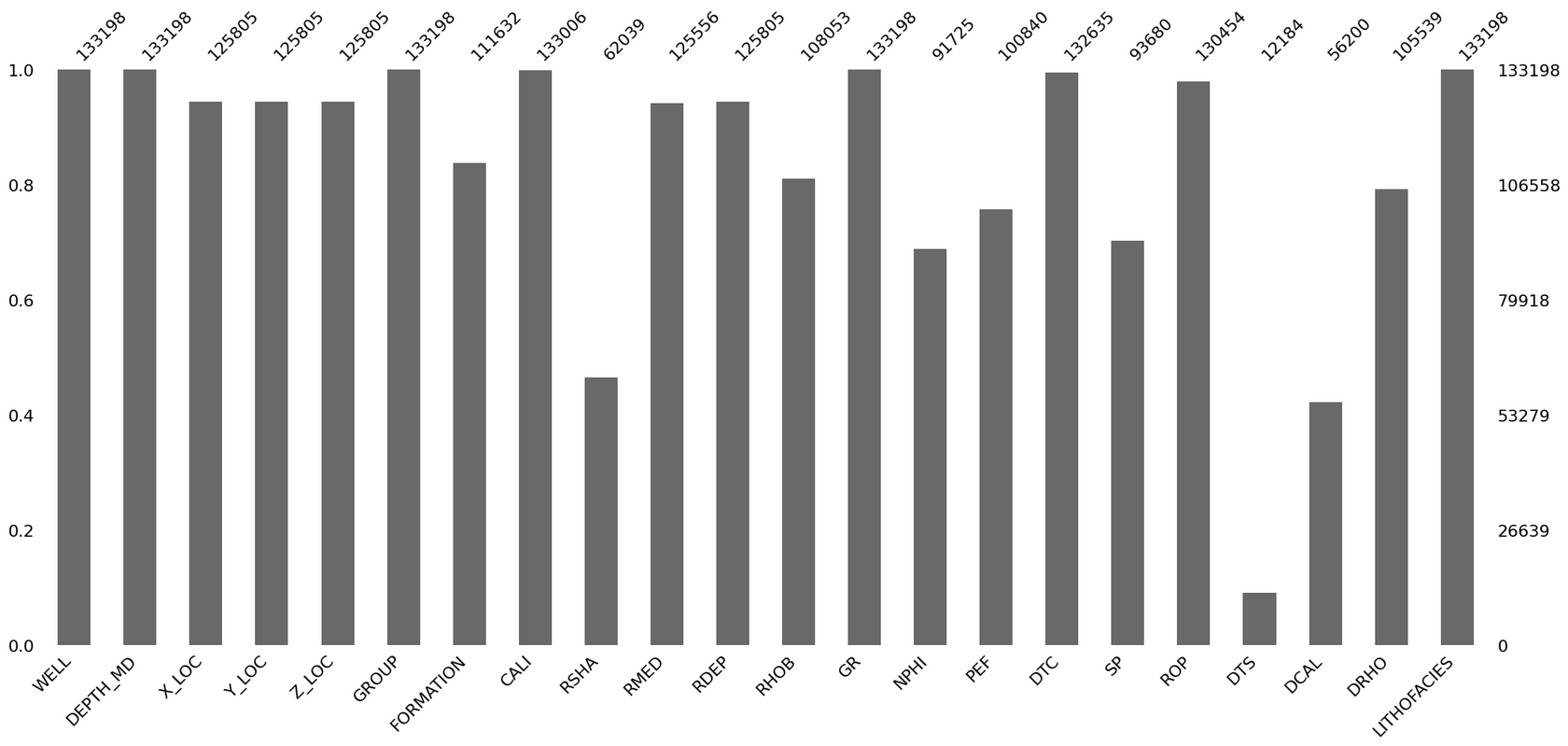
Как читать этот график:
- Ось Y (слева): Полнота данных от 0.0 (полностью пустой столбец) до 1.0 (полностью заполненный).
- Ось X: Названия столбцов датафрейма.
- Цифры над столбцами: Абсолютное количество НЕпропущенных значений в каждом столбце.
[!TIP] Когда использовать
msno.bar()? Это ваш первый шаг. Используйте его сразу после загрузки данных, чтобы получить "общую температуру по больнице" и мгновенно выявить самые проблемные столбцы, которые потребуют пристального внимания.
Этот график полезен, но он все еще не показывает расположение пропусков. Чтобы заглянуть внутрь структуры датафрейма, нам нужен следующий инструмент.
msno.matrix(): рентген вашего датафрейма
Матричный график — это, пожалуй, самый информативный инструмент в арсенале missingno. Он позволяет буквально заглянуть внутрь датафрейма и увидеть точное расположение каждого пропущенного значения.
msno.matrix(df)
plt.show()

Как читать этот график:
- Каждая строка на графике соответствует строке в вашем датафрейме.
- Столбцы — это признаки.
- Сплошные черные области — это данные, которые у нас есть.
- Белые полосы и точки — это пропуски (
NaN). - Спарклайн (sparkline) справа — это мини-график, который визуализирует полноту данных по строкам. Он показывает общую картину "здоровья" данных от начала до конца датафрейма. Линия на самом дне означает полностью заполненную строку. Чем выше поднимается линия, тем больше пропусков в соответствующем диапазоне строк.
Какие выводы можно сделать:
- Структура пропусков: Мы отчетливо видим, что пропуски — не случайный шум. В некоторых столбцах они образуют огромные сплошные белые блоки. Это говорит о том, что данные отсутствуют не точечно, а целыми сегментами. Вероятно, для определенных скважин или на определенных глубинах эти измерения просто не проводились.
- Локализация: Спарклайн справа неровный. Есть пики и впадины. Это значит, что есть целые группы строк, где данных не хватает больше, чем в других. Если бы данные были упорядочены по времени или по скважинам, это был бы мощнейший инсайт.
- Визуальное подтверждение корреляций: Присмотритесь к столбцам
X_LOC,Y_LOC,Z_LOCиRDEP. Белые горизонтальные черточки в них появляются и исчезают синхронно. Это визуальное подтверждение нашей гипотезы, сделанной на основеisna().sum(): если пропущено одно из этих значений, скорее всего, пропущены и остальные.
[!INFO] Почему матрица так важна? Матричный график переводит наш анализ с уровня "сколько" на уровень "где и как". Он незаменим для временных рядов и любых упорядоченных данных (например, геологических разрезов по глубине), так как позволяет увидеть, являются ли пропуски изолированными событиями или системными сбоями на протяжении определенных периодов/участков.
msno.heatmap(): Поиск скрытых связей
Мы уже подозреваем, что пропуски в некоторых столбцах связаны. Тепловая карта создана, чтобы измерить эту связь количественно. Она вычисляет корреляцию отсутствия данных (nullity correlation) между столбцами.
msno.heatmap(df)
plt.show()
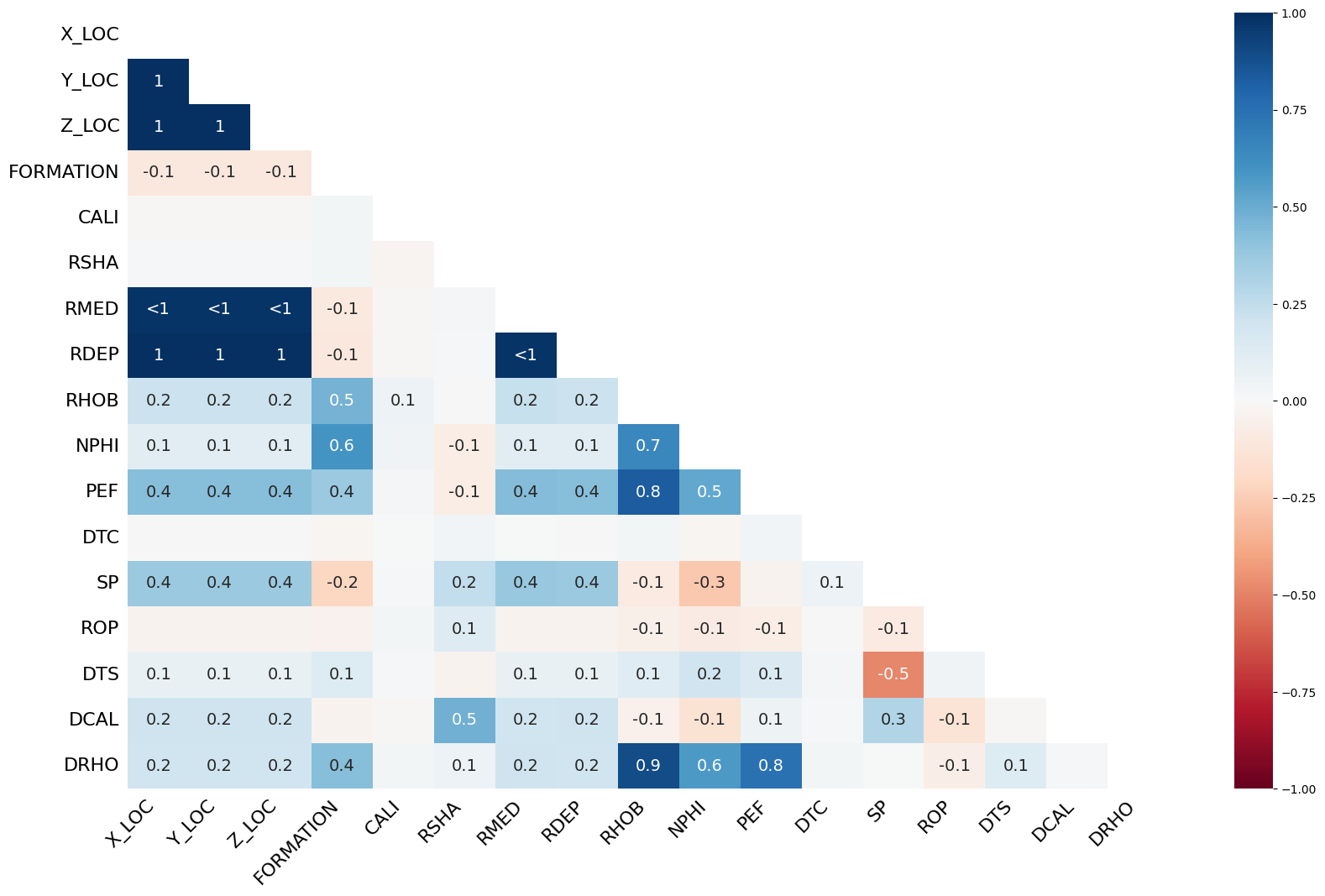
Как читать этот график:
- Это симметричная матрица, где каждый столбец сравнивается с каждым.
- Значения варьируются от -1 до 1.
- Близко к 1 (светлые тона): Сильная положительная корреляция. Если значение отсутствует в одном столбце, оно с высокой вероятностью отсутствует и в другом.
- Близко к -1: Сильная отрицательная корреляция. Если значение отсутствует в одном столбце, оно с высокой вероятностью присутствует в другом. (Встречается редко, но указывает на интересные взаимоисключающие процессы сбора данных).
- Близко к 0 (темные тона): Отсутствие корреляции. Пропуски в этих столбцах живут своей жизнью.
- Значение
<1: Если вы видите ячейку со значением, которое не равно 1, но меньше него (например, 0.8), это означает, что не все, но многие пропуски совпадают.
Какие выводы можно сделать:
- Подтвержденные кластеры: Мы видим яркий квадрат в области столбцов
RDEP,RMED,X_LOC,Y_LOC,Z_LOC. Корреляция между ними очень высока. Это означает, что данные в этих столбцах почти всегда пропадают вместе. Вероятно, они собирались в рамках одного процесса или одним набором инструментов. - Изолированные проблемы: Посмотрите на столбцы
DTSиRSHA. Они не показывают сильной корреляции с другими кластерами. Их пропуски — это отдельная история. При этом между собой они тоже не коррелируют, что интересно. - Отсутствие связей: Большинство других пар столбцов имеют корреляцию около нуля. Это говорит о том, что причины пропусков в
FORMATIONиRHOB, например, скорее всего, никак не связаны.
msno.dendrogram(): Карта родства пропусков
Дендрограмма предлагает еще один взгляд на корреляцию отсутствия данных, группируя столбцы с похожими паттернами пропусков с помощью иерархической кластеризации. Это как генеалогическое древо для ваших столбцов, где близкие родственники — это столбцы, чьи пропуски ведут себя похоже.
msno.dendrogram(df)
plt.show()
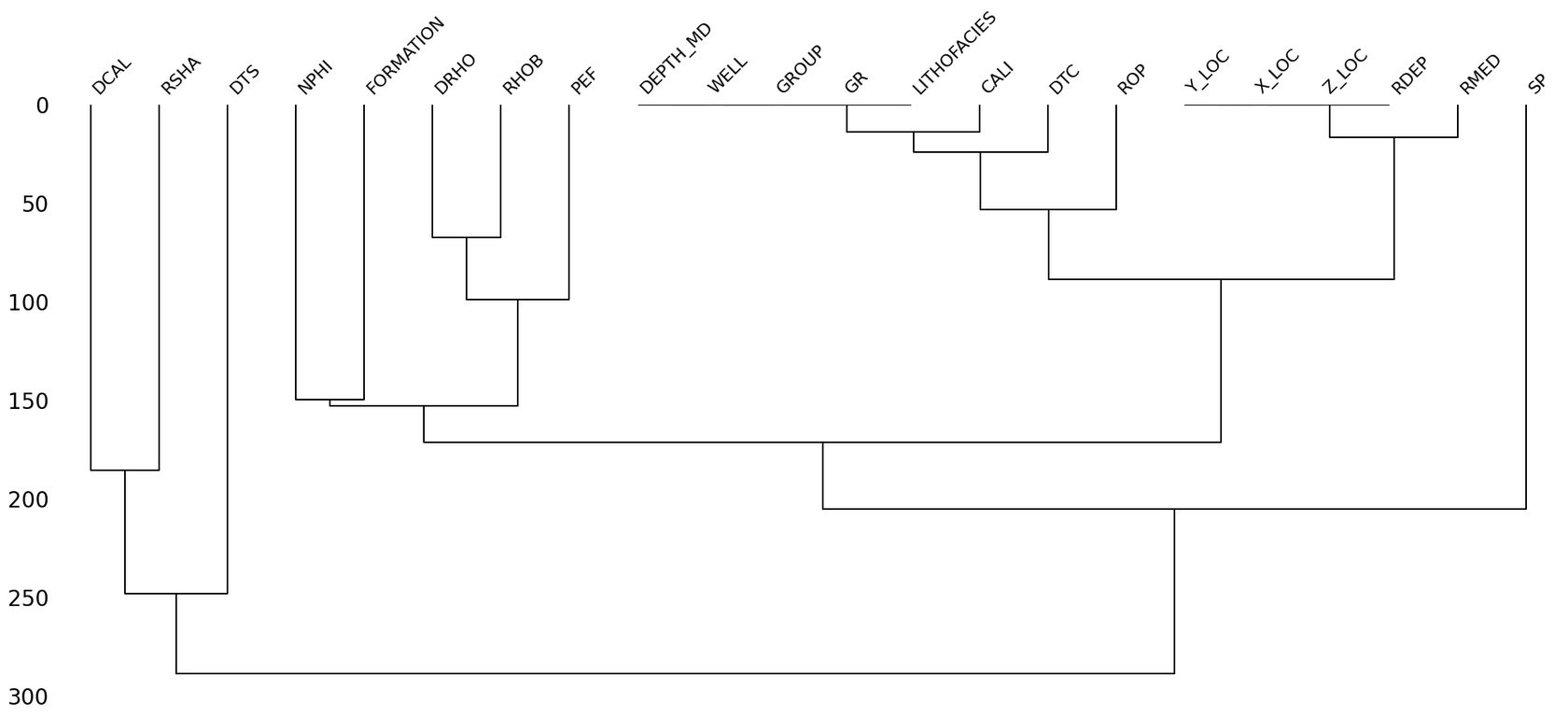
Как читать этот график:
- Древовидный граф строится снизу вверх.
- Столбцы, которые объединяются на низком уровне (ближе к 0), имеют очень схожую структуру пропусков. Горизонтальная линия, соединяющая их, показывает, на каком уровне "непохожести" они были сгруппированы.
- Чем выше по дереву происходит объединение, тем менее похожи паттерны пропусков у столбцов (или групп столбцов).
Какие выводы можно сделать:
- Клан "идеальных": мы видим плотную группу (
LITHOFACIES,GR,GROUP,WELL,DEPTH_MD), объединенную на уровне 0. Это наши полностью заполненные столбцы. Их паттерн пропусков идентичен — пропусков нет. - Клан "геопозиции": дендрограмма объединяет
X_LOC,Y_LOC,Z_LOCиRDEPна очень низком уровне, подтверждая их тесную связь.RMEDприсоединяется к этой группе чуть выше, что говорит о сильной, но не идеальной связи — именно то, что мы видели на тепловой карте. - Клан "одиночек": мы видим, что
DTS,RSHAиCALIприсоединяются к общему дереву очень высоко. Это значит, что их паттерны пропусков уникальны и не похожи ни друг на друга, ни на другие столбцы. Они — "дальние родственники" для остального набора данных.
Понравился материал?
Ваша поддержка — это энергия для новых статей и проектов. Спасибо, что читаете!
Заключение: Что делать с этими знаниями?
Мы прошли путь от простого подсчета NaN до глубокого структурного анализа. Библиотека missingno не заполняет пропуски за вас. Она делает нечто более важное — дает вам исчерпывающую информацию для принятия осознанного решения.
На основе нашего анализа можно наметить конкретный план действий:
- Столбец
DTS: Пропущено более 85% данных. Пытаться восстановить его — крайне рискованная затея, которая может привнести больше шума, чем сигнала. Наиболее разумная стратегия — удалить этот столбец. - Столбец
RSHA: Пропущено почти 50% данных. Ситуация пограничная. Можно рассмотреть его удаление или попытаться восстановить значения, но только для тех моделей, которые устойчивы к подобным манипуляциям. - Кластер
X_LOC,Y_LOC,Z_LOC,RDEP,RMED: Эти столбцы теряют данные синхронно. Это значит, что если мы решим удалить строки с пропусками (dropna), мы должны делать это с учетом всего кластера. Удаление строк, где пропущенX_LOC, почти наверняка приведет к удалению тех же строк, где пропущеныY_LOCиZ_LOC. - Столбцы с умеренным количеством пропусков (
FORMATION,CALI,RHOB): Их пропуски не сильно коррелируют друг с другом. Здесь можно применять более тонкие методы импутации (заполнения): для каждого столбца подбирать свою стратегию (например, заполнение модой для категориальногоFORMATIONи медианой/средним или даже модельным предсказанием для числовыхCALIиRHOB).
Простой вызов df.isna().sum() никогда не дал бы нам такой глубины понимания. Визуальный анализ с missingno превращает проблему пропусков из технической неприятности в интересный исследовательский квест, по итогам которого вы знаете о своих данных гораздо больше. А хорошее знание данных — это и есть ключ к построению качественных моделей.