
Новостные ленты IT-мира снова гудят. На этот раз виновник — китайская компания Zhipu AI, которая выкатила свой новый флагман: GLM-4.5. Заявки громкие: превосходство в логике, коде и агентных задачах, сравнения с топами от OpenAI и Anthropic, да еще и всё это в open-source под лицензией MIT.
Звучит слишком хорошо, чтобы быть правдой? Возможно. Но мой опыт говорит: где дым, там часто если не огонь, то хотя бы тлеющие угли серьезных технологий. Поэтому давайте без лишнего хайпа, но и без снобизма, засучим рукава и разберемся, что это за зверь, чем он силен, и главное — как его пощупать своими руками.
Что такое GLM-4.5 и почему о нем все говорят?
Если коротко, GLM-4.5 — это не одна модель, а целое семейство больших языковых моделей (LLM) от Zhipu AI. Ключевые игроки здесь два:
- GLM-4.5: Старшая модель. Архитектура — Mixture-of-Experts (MoE, или "Смесь Экспертов"). Общее число параметров — 355 миллиардов, из которых в каждый момент времени активны "всего" 32 миллиарда.
- GLM-4.5-Air: Облегченная версия. Тоже MoE, но поскромнее: 106 миллиардов общих параметров и 12 миллиардов активных.
Обе модели хвастаются контекстным окном в 128k токенов и заточены под сложные задачи, которые требуют не просто ответа, а "размышлений" — то, что сейчас модно называть agentic tasks. То есть, модель может использовать инструменты (например, вызывать функции, искать в интернете), строить сложные логические цепочки и, по сути, вести себя как автономный агент для решения проблемы.
[!INFO] Основной источник информации — официальный анонс в блоге Z.ai. Всегда полезно ознакомиться с первоисточником.
Главный же повод для ажиотажа — это комбинация трех факторов:
- Высокая производительность: Судя по бенчмаркам, модель уверенно дышит в спину признанным лидерам рынка.
- Открытость: Веса моделей выложены на HuggingFace под лицензией MIT, что позволяет использовать их в коммерческих проектах. Это серьезный шаг.
- Фокус на агентах: Модель изначально проектировалась для сложных, многоэтапных задач, что делает ее крайне интересной для разработчиков продвинутых ИИ-систем.
Бенчмарки: Верим или проверяем?
На бумаге и в маркетинговых материалах любая модель выглядит как терминатор. Давайте посмотрим на цифры, которые приводят сами создатели.
Агентные задачи (Agentic Tasks)
Здесь оценивается способность модели использовать внешние инструменты, например, для веб-браузинга или вызова функций.
| Benchmark | GLM-4.5 | Claude 4 Sonnet | GPT-4.1 | Grok 4 |
|---|---|---|---|---|
| 𝜏-bench | 70.1 | 70.3 | 62.0 | 67.5 |
| BFCL v3 (Full) | 77.8 | 75.2 | 68.9 | 66.2 |
| BrowseComp | 26.4 | 14.7 | 4.1 | 32.6 |
Что видим: В задачах на вызов функций (BFCL) и общих агентных задачах (𝜏-bench) GLM-4.5 идет вровень или даже обгоняет Claude 4 Sonnet. А вот в веб-браузинге (BrowseComp) уступает Grok 4, но при этом сокрушительно побеждает GPT-4.1.
Логика и рассуждения (Reasoning)
Это сердце любой серьезной модели. Способность решать математические, научные и логические задачи.
| Benchmark | GLM-4.5 | Claude 4 Opus | Gemini 2.5 Pro | Grok 4 |
|---|---|---|---|---|
| MMLU Pro | 84.6 | 87.3 | 86.2 | 86.6 |
| AIME24 | 91.0 | 75.7 | 88.7 | 94.3 |
| MATH 500 | 98.2 | 98.2 | 96.7 | 99.0 |
Что видим: Здесь GLM-4.5 — крепкий хорошист, но не отличник. Он стабильно показывает высокие результаты, но на самых сложных математических и логических бенчмарках уступает топовым моделям вроде Grok 4 и Claude 4 Opus.
Программирование (Coding)
Способность писать код и исправлять ошибки в существующих проектах.
| Benchmark | GLM-4.5 | Claude 4 Sonnet | Claude 4 Opus |
|---|---|---|---|
| SWE-bench Verified | 64.2 | 70.4 | 67.8 |
| Terminal-Bench | 37.5 | 35.5 | 43.2 |
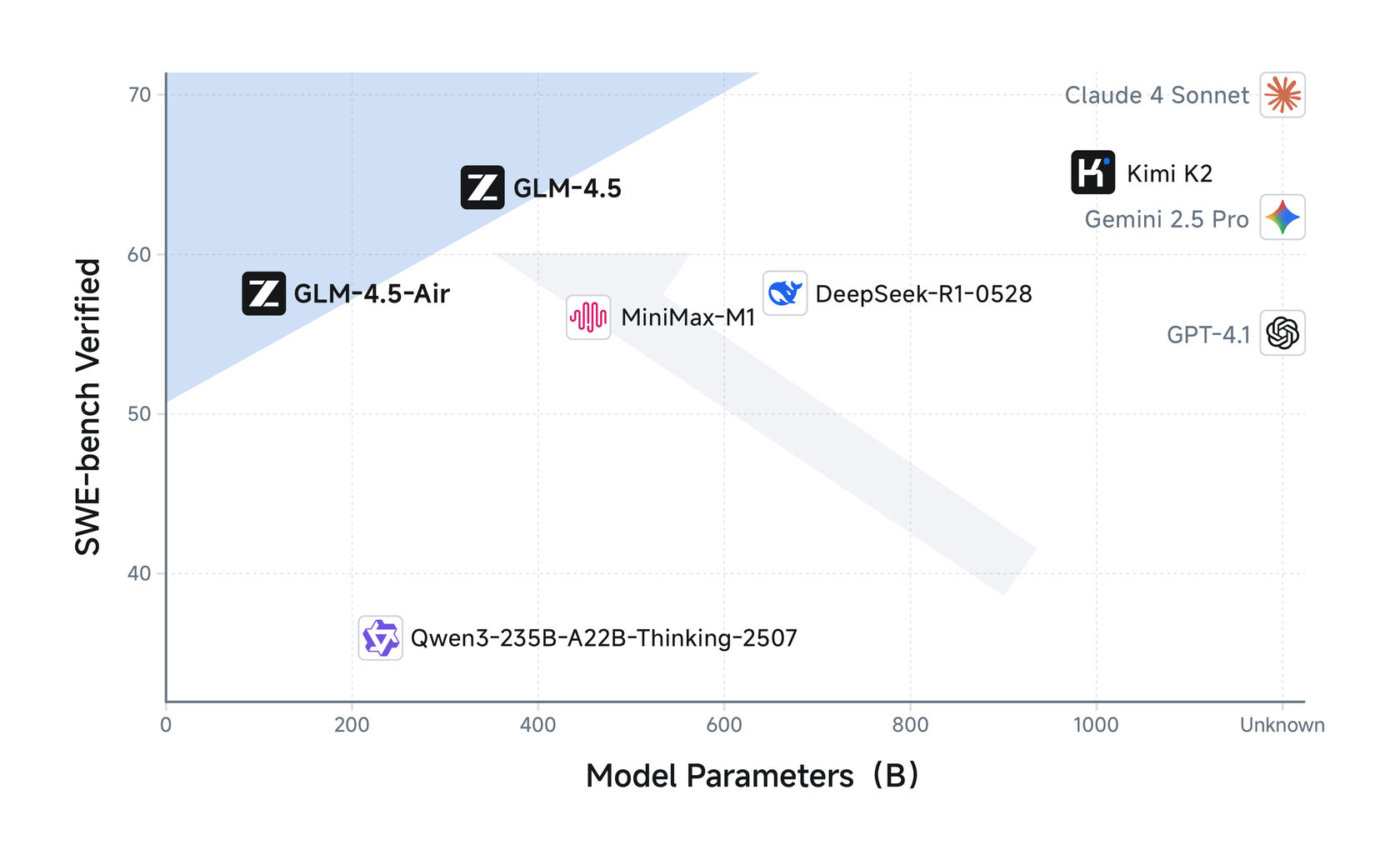
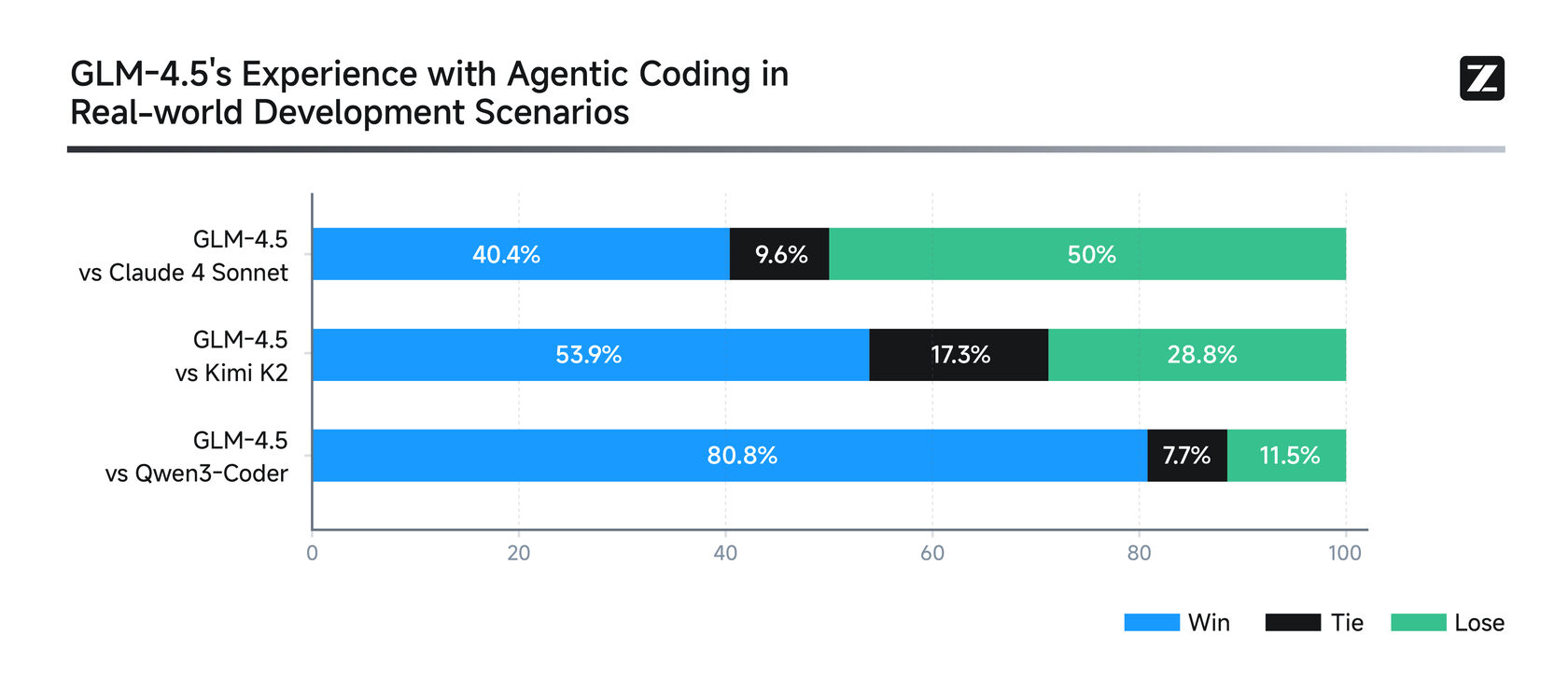
Что видим: Тут картина похожая. GLM-4.5 показывает очень достойный результат, но флагманы от Anthropic пока впереди.
[!NOTE] GLM-4.5 — это не безоговорочный "убийца" всего и вся. Это чертовски сильный игрок, который по совокупности показателей уверенно вошел в высшую лигу. Его главная сила не в том, чтобы быть №1 в каждом отдельном бенчмарке, а в том, чтобы быть очень хорошим во всем сразу, при этом оставаясь открытым.
Ключевые фичи и «вау-эффекты»
Бенчмарки — это хорошо, но часто они не показывают всей картины. Гораздо интереснее посмотреть на то, что модель умеет делать на практике. И вот тут у Zhipu AI есть несколько козырей в рукаве.
Генерация артефактов
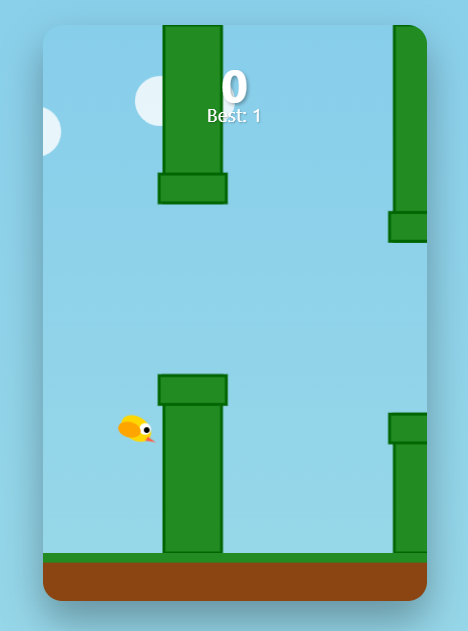
Модель способна создавать сложные, интерактивные "артефакты" — готовые куски кода на HTML/SVG/Python, которые можно сразу запустить. Самый яркий пример — игра Flappy Bird, сгенерированная по текстовому запросу. Это не просто код, а полноценное мини-приложение.
Создание презентаций
Используя свои агентные способности, GLM-4.5 может по запросу создать полноценную презентацию или постер. Модель сама ищет информацию в вебе, подбирает изображения и верстает все это в готовый HTML-файл.

Full-Stack разработка
Самое впечатляющее демо — это создание полноценного веб-приложения. Разработчики показали, как с помощью агента на базе GLM-4.5 можно создать с нуля сайт "Pokédex", включая фронтенд, бэкенд и работу с базой данных.
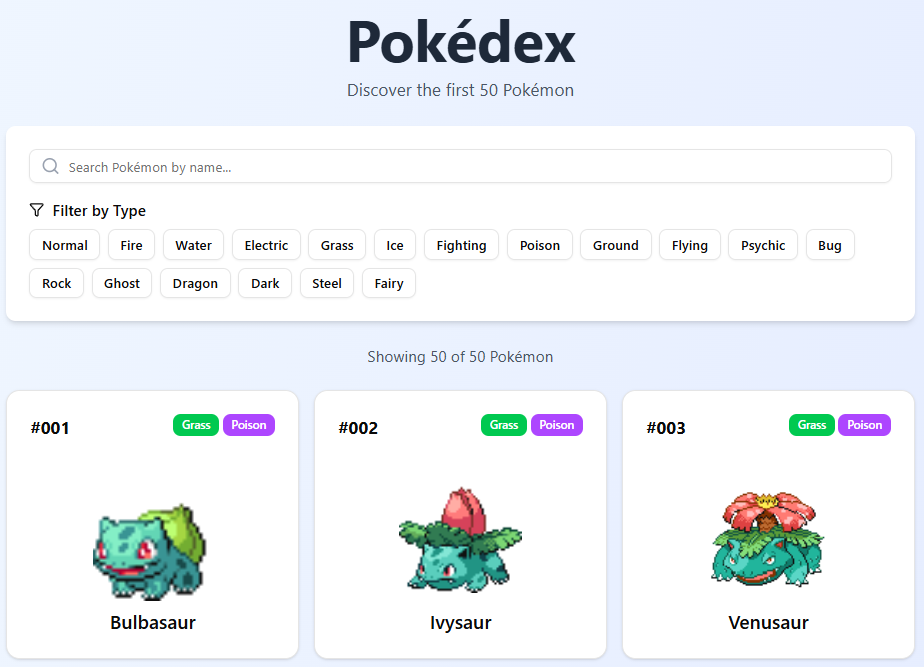
- Посмотреть на живой сайт Pokédex: Live Demo
Архитектура и технические детали: Заглянем под капот
Разработчики поделились довольно интересными деталями об архитектуре и процессе обучения, что всегда ценно для понимания сильных и слабых сторон модели.
MoE: Глубже, а не шире
В основе GLM-4.5 лежит архитектура Mixture-of-Experts (MoE). Основная идея MoE — вместо одной гигантской нейросети использовать ансамбль из более мелких "экспертных" сетей и специальный "маршрутизатор" (gate), который решает, какому эксперту отправить тот или иной токен на обработку. Это позволяет значительно увеличить общее число параметров модели, сохраняя при этом приемлемую скорость инференса, так как в каждый момент времени активна лишь малая часть весов.
[!TIP] Ключевое отличие GLM-4.5 от других MoE-моделей (вроде DeepSeek или Kimi): Команда Zhipu AI сделала ставку не на ширину (большое число экспертов), а на глубину (большее количество слоев). По их словам, это позволило улучшить способности модели к рассуждениям (
reasoning capacity).
Другие интересные архитектурные решения:
- Grouped-Query Attention (GQA): Эффективный механизм внимания, который является золотой серединой между стандартным Multi-Head Attention (MHA) и более простым Multi-Query Attention (MQA).
- Увеличенное число "голов" внимания: Контринтуитивно, но увеличение числа голов внимания (96 для скрытого слоя размером 5120) улучшило показатели на бенчмарках типа MMLU, хотя и не повлияло на общую функцию потерь при обучении.
- MTP (Multi-Token Prediction): Дополнительный слой, который позволяет реализовать спекулятивное декодирование. Это техника, при которой "маленькая" быстрая модель-черновик генерирует несколько токенов вперед, а основная "большая" модель затем проверяет их все разом. Это значительно ускоряет генерацию текста.
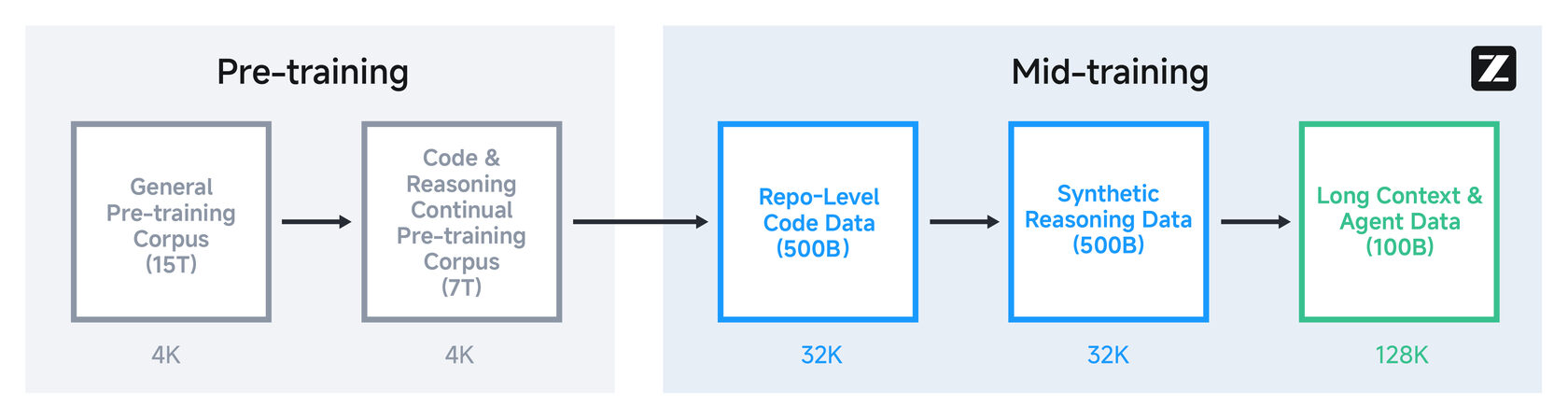
Обучение: От триллионов токенов до RL с агентами
Процесс обучения модели состоял из нескольких этапов:
- Общий Pre-training: Модель сначала "прочитала" 15 триллионов токенов из общего корпуса данных.
- Специализированный Pre-training: Затем ее дообучили на 7 триллионах токенов из корпуса, состоящего из кода и текстов, требующих рассуждений.
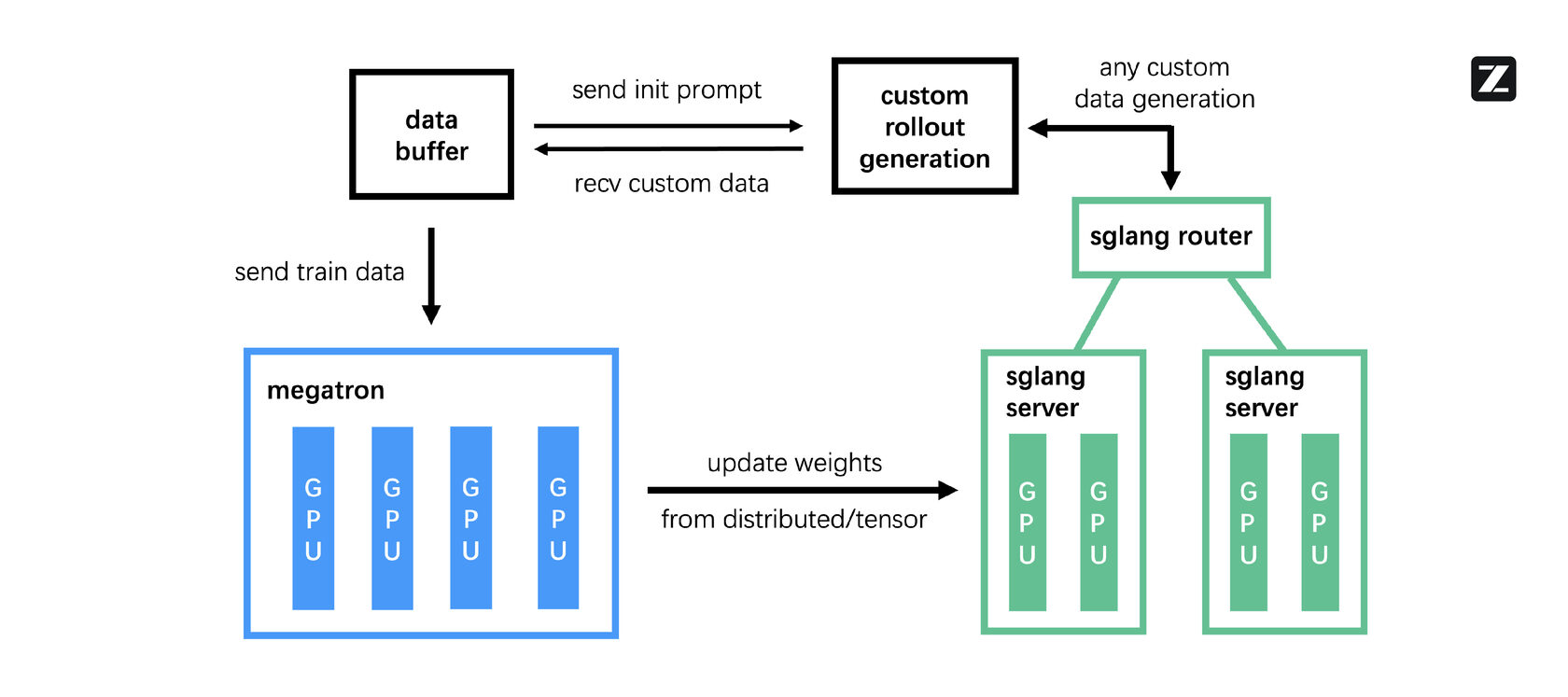
- Post-training и RL: Самый интересный этап. Здесь модель доводили до ума с помощью обучения с подкреплением (Reinforcement Learning). Для этого команда разработала и заопенсорсила собственный RL-фреймворк slime. Его ключевая особенность — асинхронная архитектура, которая позволяет эффективно обучать агентов на задачах с долгой обратной связью (например, когда нужно дождаться результатов выполнения кода или ответа от веб-страницы).
Практическое руководство: Как запустить GLM-4.5 локально
Теория — это прекрасно, но давайте перейдем к практике. Раз модель опенсорсная, значит, мы можем запустить ее у себя. Сразу предупрежу: даже для "облегченной" версии GLM-4.5-Air потребуются серьезные мощности.
Системные требования
Разработчики дают следующие ориентиры для запуска с помощью фреймворка SGLang:
| Модель | Точность | Минимальная конфигурация (короткий контекст) | Рекомендуемая конфигурация (контекст 128k) |
|---|---|---|---|
| GLM-4.5-Air | BF16 | 4x NVIDIA H100 | 8x NVIDIA H100 |
| GLM-4.5-Air | FP8 | 2x NVIDIA H100 | 4x NVIDIA H100 |
| GLM-4.5 | BF16 | 16x NVIDIA H100 | 32x NVIDIA H100 |
| GLM-4.5 | FP8 | 8x NVIDIA H100 | 16x NVIDIA H100 |
[!WARNING] Как видите, без доступа к серьезному серверному железу запустить модель не получится. Вариант с
cpu-offloadсуществует, но производительность будет крайне низкой. Наиболее "народный" вариант — этоGLM-4.5-Air-FP8на двух H100.
Пример запуска с помощью SGLang
SGLang — один из рекомендуемых фреймворков для запуска GLM-4.5. Он хорошо оптимизирован для MoE-архитектур и поддерживает спекулятивное декодирование.
1. Установка зависимостей:
pip install sglang transformers
2. Запуск сервера SGLang (для GLM-4.5-Air-FP8):
python3 -m sglang.launch_server \
--model-path zai-org/GLM-4.5-Air-FP8 \
--tp-size 4 \
--tool-call-parser glm45 \
--reasoning-parser glm45 \
--speculative-algorithm EAGLE \
--speculative-num-steps 3 \
--speculative-eagle-topk 1 \
--speculative-num-draft-tokens 4 \
--mem-fraction-static 0.7 \
--disable-shared-experts-fusion \
--served-model-name glm-4.5-air-fp8 \
--host 0.0.0.0 \
--port 8000
tp-size(tensor parallel size) нужно подбирать под вашу конфигурацию GPU. Для 4x H100 это будет4.
3. Отправка запроса на API (Python):
После запуска сервера у вас поднимается эндпоинт, совместимый с OpenAI API.
from openai import OpenAI
import json
# Клиент для подключения к нашему локальному серверу
client = OpenAI(
api_key="EMPTY",
base_url="http://127.0.0.1:8000/v1",
)
# Пример простого запроса
messages = [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Explain the importance of Mixture-of-Experts in modern LLMs."},
]
completion = client.chat.completions.create(
model="glm-4.5-air-fp8", # Указываем имя модели, которое задали при старте
messages=messages,
max_tokens=1024,
temperature=0.7,
)
print(completion.choices[0].message.content)
Пример с вызовом инструментов (Function Calling)
Сила GLM-4.5 — в агентных задачах. Вот как можно использовать вызов функций.
# ... (код клиента тот же)
tools = [
{
"type": "function",
"function": {
"name": "get_current_weather",
"description": "Get the current weather in a given location",
"parameters": {
"type": "object",
"properties": {
"location": {
"type": "string",
"description": "The city and state, e.g. San Francisco, CA",
},
"unit": {"type": "string", "enum": ["celsius", "fahrenheit"]},
},
"required": ["location"],
},
},
}
]
messages = [
{"role": "user", "content": "What's the weather like in Boston?"}
]
response = client.chat.completions.create(
model="glm-4.5-air-fp8",
messages=messages,
tools=tools,
tool_choice="auto",
)
response_message = response.choices[0].message
tool_calls = response_message.tool_calls
if tool_calls:
# Здесь модель запросила вызов инструмента
# В реальном приложении мы бы вызвали нашу функцию
# и вернули результат модели
print("===== TOOL CALL REQUESTED =====")
print(tool_calls[0].function.name)
print(json.loads(tool_calls[0].function.arguments))
В репозитории проекта на GitHub можно найти полный код для работы с API.
Понравился материал?
Ваша поддержка — это энергия для новых статей и проектов. Спасибо, что читаете!
Выводы: Место GLM-4.5 в иерархии LLM
Итак, мы рассмотрели новую модель со всех сторон. Пора подвести итоги и сделать выводы, свободные от маркетинговой шелухи.
1. Это не "убийца GPT-4", и это нормально. GLM-4.5 не превосходит топовые проприетарные модели в каждой задаче. Но он и не должен. Его главная ценность — в другом. Он сокращает разрыв между закрытыми флагманами и open-source решениями до минимума. Это чрезвычайно мощный инструмент, который теперь доступен всему сообществу.
2. Open-Source агентность — это новый тренд. Модели вроде Llama 3 сильны в общих задачах, но GLM-4.5 делает явную ставку на агентные возможности: вызов инструментов, сложные рассуждения, многошаговое выполнение задач. Это именно то, что нужно для создания следующего поколения ИИ-приложений. И то, что теперь это есть в открытом доступе — огромный плюс для индустрии.
3. "Железный" барьер все еще высок. К сожалению, демократизация ИИ пока не означает, что каждый сможет запустить флагманскую модель на своем игровом ПК. Требования к железу остаются серьезным препятствием для индивидуальных разработчиков и небольших команд. Однако для компаний, у которых есть доступ к облачным GPU или собственным серверам, GLM-4.5 становится очень привлекательной альтернативой платному API от OpenAI или Anthropic.
4. Китай как серьезная сила в Open Source AI. Zhipu AI, наряду с другими компаниями вроде 01.AI, DeepSeek и Alibaba, демонстрирует, что Китай становится не просто пользователем, а одним из ключевых драйверов в разработке открытых базовых моделей. Это усиливает конкуренцию, что всегда на руку конечному потребителю — то есть нам, разработчикам.
Выход GLM-4.5 не перевернул игру, но сделал ее намного интереснее. У нас появился еще один мощный, открытый инструмент, и теперь только от нас зависит, какие удивительные вещи мы с его помощью создадим.