
Хайп вокруг VLM-агентов, способных "видеть" и "действовать", не утихает. Но как только дело доходит до практики, встает главный вопрос: а как, собственно, измерить, какой ИИ-агент "умнее"? Прогнать его по MMLU? Скучно и нерелевантно для оценки действия в динамической среде.
Именно здесь на сцену выходят игровые бенчмарки. Игры — это идеальные песочницы: сложные, с четкими правилами, измеримыми результатами и бесконечной вариативностью. Сегодня мы не просто рассмотрим два open-source проекта для оценки VLM-агентов, а столкнем лбами две фундаментально разные философии их тестирования.
С одной стороны у нас VideogameBench — проект, проверяющий широту компетенций, своего рода "декатлон" для ИИ. С другой — LLM Colosseum, который тестирует глубину тактического мышления и скорость реакции.
Так что же важнее для современного VLM-агента: быть эрудитом, способным пройти и Civilization, и Zelda, или быть мастером одного дела, молниеносно принимающим решения в Street Fighter? Давайте разбираться.
Концептуальное поле битвы: эрудиция против рефлексов
Прежде чем лезть в код и архитектуру, важно понять идеологическую разницу подходов. От нее зависят и выбор игр, и метрики, и даже стиль промптов.
VideogameBench: Подход "Декатлониста"
VideogameBench (VGB) ставит перед моделью глобальную задачу: доказать свою общую компетентность в максимально разнообразных условиях.

- Набор дисциплин: Включает игры разных жанров: RTS (Civilization, Age of Empires), платформеры (Kirby's Dream Land), RPG (Pokémon Crystal, Zelda), FPS (Doom II) и даже головоломки (The Incredible Machine).
- Ключевой вопрос: Способен ли агент, получив инструкцию, понять принципиально разные механики, адаптироваться к разным интерфейсам (текстовые меню, point-and-click, управление персонажем в реальном времени) и достичь конкретных, заранее определенных целей (чекпоинтов)?
- Аналогия: Это как проверка выпускника вуза на способность применять знания в разных сферах — от написания бизнес-плана до базового программирования. Тестируется адаптивность и широта когнитивных навыков.
Агент должен показать, что он может быть и стратегом, и тактиком, и исследователем.
LLM Colosseum: Подход "Боксера-Профессионала"
LLM Colosseum исповедует совершенно иную философию. Он не распыляется на жанры.

- Дисциплина: Только одна, но доведенная до предела — файтинг Street Fighter III: 3rd Strike.
- Ключевой вопрос: Может ли агент в сверхдинамичной среде, где решения нужно принимать за доли секунды, не просто нажимать на кнопки, а демонстрировать тактическое мышление, предугадывать действия оппонента и выполнять сложные комбинации?
- Аналогия: Это спарринг двух гроссмейстеров. Неважно, умеют ли они играть в "Монополию". Важна только глубина понимания одной сложной системы и скорость реакции.
Здесь не нужно учиться новому; нужно довести до совершенства имеющиеся навыки в условиях жесткого противостояния.
Оба подхода имеют право на жизнь, но они тестируют совершенно разные аспекты "интеллекта" VLM-агента. Теперь посмотрим, как эти философские различия реализуются на техническом уровне.
Архитектура и технический стек: Два мира, два подхода
Философские различия неизбежно ведут к разным техническим решениям.
VideogameBench: Гибкость эмуляции через Python и веб-автоматизацию
VGB использует два совершенно разных подхода к эмуляции, что подчеркивает его фокус на адаптивности агента.
1. Игры для Game Boy (GBA): Для классики вроде Zelda или Pokémon Crystal используется библиотека PyBoy. Это нативный Python-эмулятор, что дает огромное преимущество в простоте интеграции. Взаимодействие с игрой происходит через прямые вызовы API.
В файле src/emulators/gba/interface.py мы видим, как текстовые команды агента мапятся на конкретные события эмулятора:
BUTTON_MAP = {
'A': WindowEvent.PRESS_BUTTON_A,
'B': WindowEvent.PRESS_BUTTON_B,
'SELECT': WindowEvent.PRESS_BUTTON_SELECT,
'START': WindowEvent.PRESS_BUTTON_START,
'RIGHT': WindowEvent.PRESS_ARROW_RIGHT,
# ... и так далее
}
Агент думает: "нажать A", и скрипт выполняет pyboy.send_input(WindowEvent.PRESS_BUTTON_A). Просто, быстро и надежно.
2. Игры для MS-DOS: А вот для DOS-игр вроде Doom II или Civilization выбран нетривиальный путь. Игры запускаются в эмуляторе JS-DOS, который работает прямо в браузере. Агент взаимодействует с этим браузером через Playwright — фреймворк для веб-автоматизации.
Агент генерирует JSON-подобные команды, которые затем парсятся и исполняются BrowserController'ом:
{
"thought": "I need to move the character left in the game",
"action": "press_key",
"action_input": "ArrowLeft"
}
Для мыши агент указывает координаты ("action": "move_mouse", "action_input": "320,200"), а Playwright имитирует человекоподобное движение курсора по canvas элемента браузера.
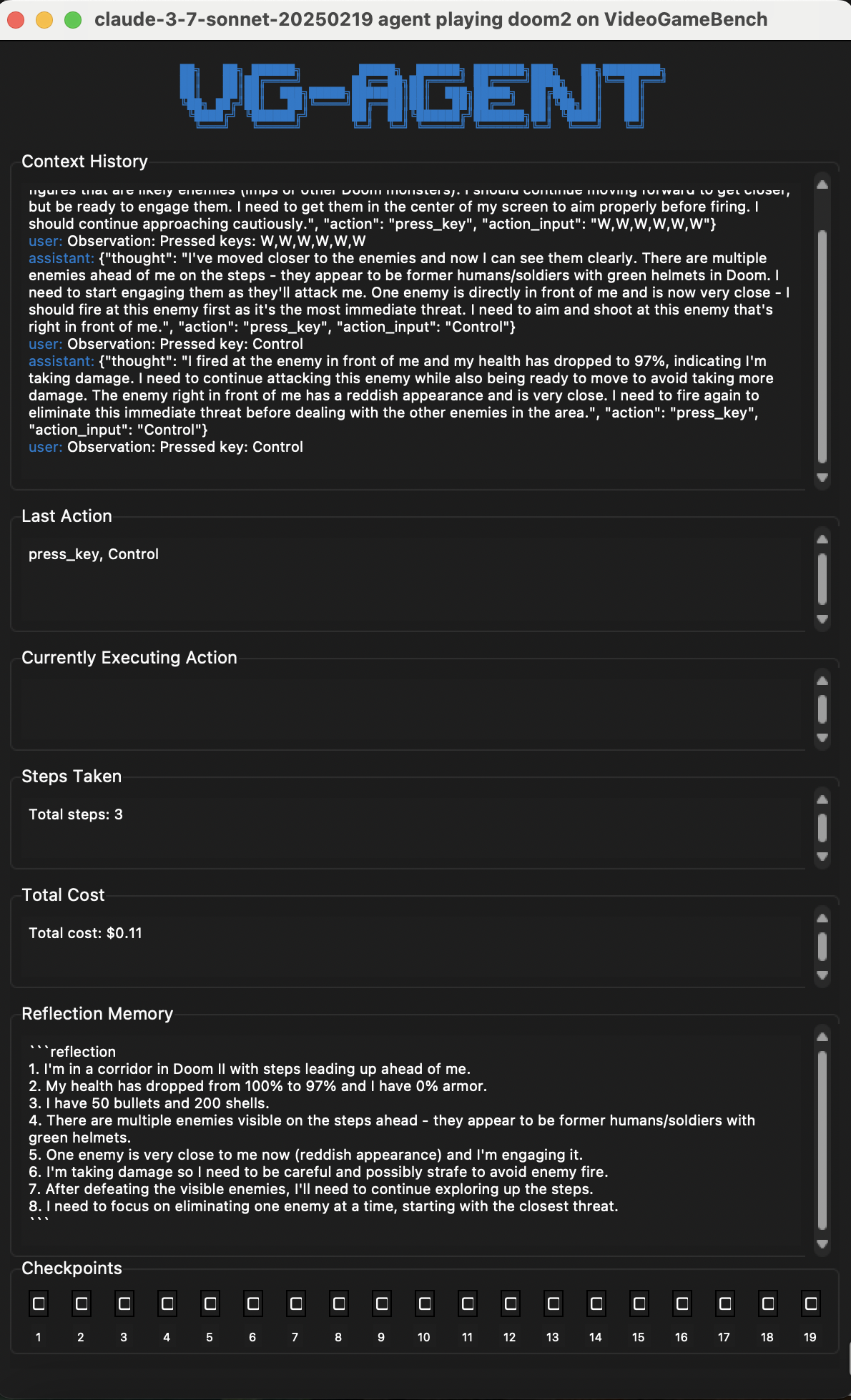
[!INFO] Черный ящик против прямого доступа
Ключевое различие: для GBA-игр у агента есть потенциальный доступ "внутрь" эмулятора (память, состояние). Для DOS-игр эмулятор — это полный черный ящик (веб-страница), и единственные каналы взаимодействия — это скриншот на вход и симуляция нажатий на выход. Это заставляет VLM-агента полагаться исключительно на зрение, как это делал бы человек.
LLM Colosseum: Стабильность и структурированность Diambra Arena
LLM Colosseum не изобретает велосипед, а берет готовое, проверенное в боях решение — Diambra Arena. Это платформа, построенная на базе эмуляторов MAME и RetroArch, специально заточенная для соревнований ИИ в играх.
- Среда: Diambra предоставляет стабильную и стандартизированную среду. Это исключает множество потенциальных проблем, связанных с кастомными эмуляторами или веб-автоматизацией (задержки, "плавающие" элементы и т.д.).
- Взаимодействие: Агент также генерирует команды, но они более высокоуровневые. Вместо
"нажать Вниз, Вперед, Удар", агент может сказать"Fireball". В файлеagent/config.pyэти мета-инструкции уже разложены на последовательности нажатий:
COMBOS = {
"Fireball (Hadouken)": {"right": [7, 6, 5, 10], "left": [7, 8, 1, 10]},
# ...
}
- Наблюдение (Observation): И вот здесь кроется главное архитектурное отличие. Агент в LLM Colosseum получает не только скриншот. Метод
observeвagent/robot.pyтакже извлекает из эмулятора структурированные данные:character_position: координаты своего персонажа.ennemy_position: координаты противника.super_bar_own: уровень своей шкалы "супер-удара".health: уровень здоровья обоих игроков.
Эти данные потом явно передаются в промпт. То есть агент не должен угадывать по картинке, где он находится или сколько у него здоровья, — он это знает. Это смещает фокус с распознавания образов на чистое тактическое принятие решений.
Методы оценки: Чекпоинты против ELO-рейтинга
Как проекты определяют победителя? Здесь их пути снова расходятся.
VideogameBench: Прогресс по контрольным точкам
VGB использует систему чекпоинтов (checkpoints). Для каждой игры подготовлен набор эталонных скриншотов, которые соответствуют ключевым моментам прохождения.
- Как это работает: После каждого действия агента
DOSEvaluatorилиGBEvaluatorберет текущий скриншот с экрана. Затем этот скриншот сравнивается с хэшем следующего чекпоинта из списка. - Технология сравнения: Для сравнения используется перцептивный хэш (
imagehash.average_hash). Вместо попиксельного сравнения, которое чувствительно к малейшим артефактам, p-hash создает "отпечаток" изображения. Функцияis_same_hashвsrc/utils.pyсчитает расстояние Хэмминга между хэшами. Если оно меньше заданного порога (threshold), чекпоинт считается пройденным.
def is_same_hash(img_hash: ImageHash, ref_hash: ImageHash, threshold: int = 1, verbose: bool = False) -> bool:
# Hamming distance
dist = img_hash - ref_hash
if verbose:
print("Current hash dist:", dist, dist <= threshold, threshold)
return dist <= threshold
- Плюсы:
- Объективность: Четко и однозначно определяет, достигнута ли цель.
- Простота: Легко реализовать и добавить новые чекпоинты.
- Независимость от пути: Неважно, как агент дошел до точки, важен сам факт.
- Минусы:
- Жесткость: Если агент прошел игру альтернативным путем или на экране есть незначительный визуальный "шум" (например, другой эффект заклинания), чекпоинт может не засчитаться.
- Не оценивает "качество" прохождения: Пройти уровень с полной жизнью или на последнем издыхании — для системы чекпоинтов это одно и то же.
LLM Colosseum: Рейтинг Эло как в шахматах
LLM Colosseum, как и подобает соревновательной платформе, использует рейтинговую систему Эло. Это классический подход из мира шахмат и киберспорта для оценки относительной силы игроков.
- Как это работает:
- Все модели-участники ("игроки") начинают с одинакового базового рейтинга (например, 1500).
- Проводится серия матчей, где модели играют друг против друга.
- После каждого матча рейтинг победителя и проигравшего обновляется.
- Механика обновления: Функция
elo_updateвeval/game.pyреализует стандартную формулу Эло. Рейтинг изменяется в зависимости от:- Исхода матча: Победа или поражение.
- Ожидаемого исхода: Если игрок с низким рейтингом побеждает игрока с высоким, он получает много очков, а его оппонент много теряет. Если фаворит побеждает аутсайдера, изменение очков минимально.
def elo_update(winner_rating, loser_rating, k=32):
expected_score_winner = elo_expected_score(winner_rating, loser_rating)
# ...
new_winner_rating = winner_rating + k * (1 - expected_score_winner)
new_loser_rating = loser_rating + k * (0 - expected_score_loser)
return new_winner_rating, new_loser_rating
- Плюсы:
- Относительная сила: Показывает не абсолютное "умение", а силу одной модели относительно других.
- Динамичность: Рейтинг постоянно обновляется с каждым новым матчем и новым участником.
- Устойчивость к случайностям: Одна случайная победа или поражение не сильно влияют на общую картину после длинной серии игр.
- Минусы:
- Затратность: Требует большого количества матчей между всеми парами участников для получения стабильного рейтинга.
- "Инфляция" рейтинга: Со временем средний рейтинг может смещаться.
- Не оценивает PvE навыки: Этот метод подходит только для соревновательных игр (PvP).
Понравился материал?
Ваша поддержка — это энергия для новых статей и проектов. Спасибо, что читаете!
Финальный вердикт: Кто кого?
Так какой же бенчмарк "лучше"? Ответ: оба. Они не конкуренты, а взаимодополняющие инструменты.
VideogameBench — это идеальный инструмент для оценки базовой когнитивной гибкости VLM-агента. Он отвечает на вопрос: "Эта модель вообще способна обучаться и действовать в разнообразных мирах?". Это необходимый входной тест для любого универсального агента. Если модель не может пройти Kirby, нет смысла ставить ее управлять роботом-пылесосом.
LLM Colosseum — это инструмент для тонкой настройки и сравнения уже состоявшихся агентов в условиях высокого стресса. Он отвечает на вопрос: "Какая из этих двух моделей быстрее и тактически грамотнее?". Это идеальный бенчмарк для задач, где важна скорость реакции и глубина планирования в узкой области, например, в биржевом трейдинге или управлении дронами.
Вместе они дают объемную картину возможностей VLM:
- Сначала прогоняем модель через VGB, чтобы понять, есть ли у нее "общий интеллект".
- Затем стравливаем лучших "выпускников" VGB в LLM Colosseum, чтобы выявить чемпиона по скорости и тактике.
Будущее, очевидно, за гибридными бенчмарками, которые смогут измерять и широту, и глубину. Но уже сегодня, благодаря таким open-source проектам, мы можем перестать гадать на кофейной гуще и начать измерять реальные способности ИИ-агентов.