
Если вы работаете с данными в Python, то, скорее всего, ваша правая рука (а может, и левая) – это библиотека Pandas. Часто данные поступают нам в одном формате, а для эффективного анализа, визуализации или моделирования требуется совершенно другой. И важно уметь делать преобразования между "длинным" (long) и "широким" (wide) форматами датаферйма.
Мы не только подробно разберем, что представляют собой длинный и широкий форматы, но и освоим два ключевых инструмента Pandas для их взаимного преобразования: `pivot_table` и `melt`.
Длинный и широкий форматы данных
Прежде чем мы погрузимся в применение конкретных функций, необходимо подробнее обсудить оба формата представления данных: длинный и широкий. Давайте рассмотрим, как устроен каждый из них и где они обычно применяются.
Длинный формат: каждое наблюдение – отдельная строка
Представьте, что вы ведете подробный дневник наблюдений за погодой. Каждый день вы записываете: дату, температуру утром, температуру днем, температуру вечером, влажность, скорость ветра и так далее. Если бы вы решили каждое отдельное измерение (например, "температура утром") записывать в новую строку, дублируя при этом дату, то вы бы получили типичный пример длинного формата данных.
Ключевые структурные характеристики:
Типичные примеры:
- Одна строка – одно наблюдение/измерение: Основной принцип заключается в том, что каждая строка содержит информацию об одном конкретном факте, событии или единичном измерении.
- Повторяющиеся идентификаторы: Часто присутствуют один или несколько столбцов-идентификаторов (например, ID объекта, временная метка, номер серии), значения в которых могут дублироваться для разных строк, если эти строки относятся к одному и тому же объекту, но описывают разные его аспекты или состояния в разные моменты.
Типичные примеры:
- Данные временных рядов: Например, те же записи о ежедневных показаниях температуры, биржевые котировки (каждая строка – цена акции в конкретный момент времени), или данные о ежемесячных продажах каждого продукта (каждая строка – продажи одного продукта за один месяц).
- Логи событий: Системные логи, логи веб-сервера или записи о действиях пользователей в приложении, где каждая строка фиксирует одно конкретное событие с его атрибутами (например, временная метка, тип события, идентификатор пользователя, параметры события).
- Данные с сенсоров и измерительных приборов: Когда несколько датчиков регулярно передают показания (например, температура, влажность, давление), каждое отдельное показание от каждого датчика в определенный момент времени может быть представлено отдельной строкой.
- Результаты экспериментов с многократными измерениями: Если в ходе научного эксперимента для каждого образца или участника измеряется несколько различных параметров, или один и тот же параметр измеряется многократно в разные моменты времени или при разных условиях, эти индивидуальные измерения часто собираются и хранятся в длинном формате.
- Данные опросов с множественным выбором или повторяющимися блоками: Если респондент может выбрать несколько вариантов ответа на один вопрос, или если одинаковый блок вопросов задается для нескольких объектов (например, для каждого ребенка в семье), данные могут быть структурированы так, что каждый выбранный вариант или каждый ответ для каждого объекта формирует отдельную строку.
Широкий формат: каждая уникальная сущность – строка, ее характеристики – столбцы
Теперь давайте представим другую ситуацию. Вы проводите опрос среди студентов и для каждого студента (уникальная сущность) собираете информацию по ряду характеристик: возраст, курс, средний балл по математике, средний балл по программированию, участие в олимпиадах (да/нет). Если вы запишете это так, что каждая строка – это один студент, а каждая характеристика (возраст, балл по математике и т.д.) – это отдельный столбец, то вы получите широкий формат данных.
Ключевые структурные характеристики:
Типичные примеры:
Ключевые структурные характеристики:
- Одна строка – одна уникальная сущность/объект: Каждая строка в таблице представляет один и только один уникальный объект или субъект наблюдения.
- Уникальные идентификаторы строк: Обычно присутствует один или несколько столбцов, которые вместе формируют уникальный идентификатор (первичный ключ) для каждой строки, гарантируя отсутствие дублирования сущностей.
- Множество столбцов для различных характеристик/переменных: Каждая отдельная характеристика, измеренное значение или атрибут, относящийся к сущности в данной строке, располагается в своем собственном, отдельном столбце.
Типичные примеры:
- Анкетные данные или результаты опросов (простой случай): Когда каждый респондент заполняет анкету, и для каждого вопроса есть один ответ, данные часто собираются так, что каждая строка – это один респондент, а каждый столбец – ответ на конкретный вопрос (например, 'Возраст', 'Пол', 'Образование').
- Таблицы характеристик объектов: Например, база данных продуктов, где каждая строка – это один продукт, а столбцы – это его атрибуты ('Наименование', 'Цена', 'Вес', 'Цвет', 'Производитель').
- Сводные отчеты и агрегированные данные: Часто результаты агрегации данных (например, итоговые продажи по каждому региону за год, средние показатели по каждому отделу) представляются в широком формате, где каждая строка – это агрегируемая единица (регион, отдел), а столбцы – различные агрегированные показатели.
- Данные из электронных таблиц (например, Excel), созданные для человеческого восприятия: Люди часто организуют данные в электронных таблицах интуитивно в широком формате, так как он позволяет легко видеть все связанные атрибуты одного объекта в одной строке.
- Данные для некоторых статистических процедур или моделей машинного обучения: Наборы данных, подготовленные для многих классических статистических анализов или для обучения моделей машинного обучения, часто имеют структуру "объекты-признаки", где каждая строка – это объект, а каждый столбец – это признак (фича), что соответствует широкому формату.
- Финансовые отчеты: Балансовые отчеты, отчеты о прибылях и убытках часто имеют структуру, где строки представляют статьи отчета, а столбцы – значения этих статей за разные периоды или по разным категориям, что является разновидностью широкого формата.
Широкий формат интуитивно понятен, когда мы смотрим на таблицу и хотим видеть все основные характеристики одного объекта в одной строке. Однако он может быть менее гибким для добавления новых типов измерений (потребуется добавлять новые столбцы) и менее эффективным для хранения, если многие ячейки остаются пустыми (разреженные данные).
Наглядный пример
Давайте рассмотрим один и тот же гипотетический набор данных о продажах книг, представленный в обоих форматах. Предположим, у нас есть данные о продажах двух книг ("А" и "Б") в двух магазинах ("X" и "Y") за январь и февраль.
В длинном формате каждая строка представляет продажи одной книги в одном магазине за один месяц:
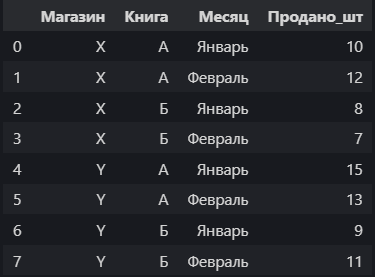
Обратите внимание: идентификаторы (Магазин, Книга, Месяц) повторяются, а Продано_шт — это измеряемая величина.
А в широком формате мы могли бы, например, сделать месяцы столбцами, а строки — это комбинация магазина и книги.
А в широком формате мы могли бы, например, сделать месяцы столбцами, а строки — это комбинация магазина и книги.
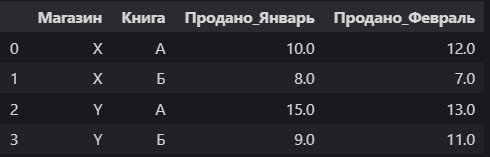
Здесь каждая строка уникальна по комбинации `Магазин и Книга`, а продажи за разные месяцы разнесены по отдельным столбцам. В длинном формате у нас больше строк, но меньше столбцов, описывающих сами данные. В широком — строк меньше (если мы группируем по магазину и книге), но появляются новые столбцы для каждого месяца.
Понимание этих различий критически важно, так как от выбора формата часто зависит, насколько легко и эффективно вы сможете выполнить следующую операцию: будь то построение графика, статистический анализ или подготовка данных для модели машинного обучения.
Понимание этих различий критически важно, так как от выбора формата часто зависит, насколько легко и эффективно вы сможете выполнить следующую операцию: будь то построение графика, статистический анализ или подготовка данных для модели машинного обучения.
Подготовка к работе: используем датасет flights
Чтобы наши примеры были не только понятными, но и воспроизводимыми, мы воспользуемся одним из встроенных наборов данных библиотеки Seaborn – `flights`. Этот датасет содержит информацию о количестве авиапассажиров (в тысячах) по месяцам за несколько лет. Он достаточно прост, чтобы не запутаться в деталях, и в то же время идеально подходит для демонстрации превращений из длинного формата в широкий и обратно.
Датасет содержит три основных столбца:
- `year`: год наблюдения (например, 1949, 1950, ...).
- `month`: месяц наблюдения (например, 'Jan', 'Feb', ..., 'Dec'). В Pandas этот столбец обычно имеет категориальный тип.
- `passengers`: количество пассажиров (в тысячах) за указанный год и месяц.
Первым шагом будет загрузка нашего набора данных. Если у вас установлены библиотеки Pandas и Seaborn, это делается буквально в две строки кода.
import pandas as pd
import seaborn as sns
# Загружаем датасет flights
flights_df = sns.load_dataset('flights')Теперь давайте проведем небольшую разведку – посмотрим, что же там внутри. Для этого используем несколько стандартных методов Pandas:
Давайте выполним этот код и посмотрим на вывод:
- `flights_df.shape` – покажет нам размеры датафрейма (количество строк и столбцов).
- `flights_df.head()` – покажет нам первые несколько строк, чтобы составить общее представление.
- `flights_df.info()` – предоставит сводную информацию о типах данных в каждом столбце и о наличии пропущенных значений.
Давайте выполним этот код и посмотрим на вывод:
# Узнаем размеры датафрейма
print(flights_df.shape)
# (144, 3)
# Посмотрим на первые 5 строк
display(flights_df.head())
# Получим информацию о датафрейме
flights_df.info()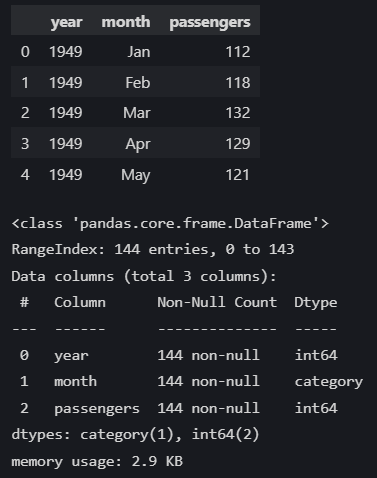
Что мы видим?
Обратите внимание, как организованы данные. Каждая строка представляет собой одно наблюдение: количество пассажиров за конкретный месяц конкретного года. Годы и месяцы повторяются. Например, для года 1949 будет 12 записей (по одной на каждый месяц), затем для 1950 года снова 12 записей, и так далее. Это и есть классический длинный формат, о котором мы говорили. У нас есть идентификаторы (`year`, `month`) и измеряемое значение (`passengers`).
Начнем с превращения этого "длинного" списка в "широкую" таблицу, где информация будет представлена более компактно для определенных видов анализа.
- `year` и `passengers` имеют числовой тип `int64`, а `month` – это `category`. Категориальный тип для месяца очень удобен, так как Pandas будет автоматически учитывать правильный порядок месяцев при некоторых операциях (например, при сортировке или построении графиков).
- Пропущенных значений нет (144 non-null count для всех столбцов).
Обратите внимание, как организованы данные. Каждая строка представляет собой одно наблюдение: количество пассажиров за конкретный месяц конкретного года. Годы и месяцы повторяются. Например, для года 1949 будет 12 записей (по одной на каждый месяц), затем для 1950 года снова 12 записей, и так далее. Это и есть классический длинный формат, о котором мы говорили. У нас есть идентификаторы (`year`, `month`) и измеряемое значение (`passengers`).
Начнем с превращения этого "длинного" списка в "широкую" таблицу, где информация будет представлена более компактно для определенных видов анализа.
Из длинного формата в широкий
Что, если мы хотим посмотреть на данные иначе? Например, представить их в виде таблицы, где по строкам идут годы, по столбцам – месяцы, а на пересечении – соответствующее количество пассажиров. Это классический пример преобразования из длинного формата в широкий. И для этой задачи в Pandas есть подходящий инструмент – функция `pivot_table`.
Функция pivot_table
`pivot_table` позволяет очень гибко определять, какие столбцы станут новыми индексами (строками), какие – новыми столбцами, а какие – значениями в ячейках. А если при преобразовании возникает ситуация, когда для одной комбинации новых строк и столбцов существует несколько значений в исходных данных, `pivot_table` может их агрегировать.
`pivot_table` также легко справляется с созданием многоуровневых (иерархических) индексов и колонок, если вы указываете несколько столбцов для index или columns.
`pivot_table` также легко справляется с созданием многоуровневых (иерархических) индексов и колонок, если вы указываете несколько столбцов для index или columns.
В Pandas есть также функция `pd.pivot()`. Она проще, чем `pivot_table()`, и предназначена для случаев, когда вы уверены, что каждая комбинация `index` и `columns` в вашем новом, широком датафрейме будет уникальной (то есть, не потребуется агрегация).
В большинстве случаев, особенно при исследовании данных, `pivot_table` является более безопасным и универсальным выбором, так как она явно обрабатывает возможные сценарии с дубликатами. Для нашего датасета flights комбинация `(year, month)` уникальна, поэтому технически здесь сработал бы и `pivot()`. Но мы будем использовать pivot_table как более общую практику.
Основные параметры pivot_table
Разумеется, первым делом `pivot_table` ожидает сам датафрейм на вход (параметр `data`, обычно передается первым позиционно).
Какие есть ещё важные параметры?
Какие есть ещё важные параметры?
- index: Этот параметр определяет, какие уникальные значения из указанного столбца (или столбцов) исходных данных станут метками строк вашей новой таблицы. По сути, вы выбираете, что будет "осью Y" вашей сводной таблицы.
- columns: Аналогично, `columns` решает, какие значения из другого столбца превратятся в заголовки столбцов новой таблицы – ваша "ось X".
- values: Этот параметр указывает, данные из какого столбца будут заполнять ячейки на пересечении этих новых строк и столбцов. Это "начинка" вашей таблицы.
Но что, если на одно пересечение новой строки и столбца претендует несколько значений из `values` в исходном датафрейма? Здесь на сцену выходит `aggfunc` (сокращение от aggregate function) – ключевой параметр, отвечающий за агрегацию. Как можно агрегировать значения?
- Сложить их (`sum`) – частый выбор, если значения числовые и их нужно суммировать.
- Усреднить (`mean`) – используется по умолчанию, если `aggfunc` не указан.
- Посчитать их количество (`count`).
- Взять первое (`first`) или последнее (`last`) из встретившихся.
Дополнительные полезные "настройки":
- fill_value: Позволяет заменить стандартные NaN (пропуски), возникающие для отсутствующих комбинаций `index`/`columns`, на более подходящее значение (например, 0).
- margins: Если установить в `True`, добавит итоговые строки и столбцы (например, "Всего"), рассчитанные с помощью той же `aggfunc`.
Теперь давайте применим эти знания на практике к нашему датасету `flights`.
Применяем pivot_table()
Поставим цель – получить датафрейм, который будет выглядеть как таблица с расписанием или сводный отчет:
- Строки (индекс) должны представлять годы (`year`).
- Столбцы должны представлять месяцы (`month`).
- Значения в ячейках таблицы должны показывать количество пассажиров (`passengers`) за соответствующий год и месяц.
Для этого мы передадим имена столбцов `year`, `month` и `passengers` в параметры `index`, `columns` и `values` функции `pivot_table` соответственно. Поскольку мы знаем из нашего предварительного анализа (и из природы датасета `flights`), что для каждой уникальной комбинации года и месяца у нас есть только одно значение количества пассажиров, любая агрегирующая функция, которая просто вернет это единственное значение, подойдет. Например, 'sum' (сумма одного числа – это само число), 'mean', 'first' или 'last'. Мы выберем 'sum' для явности, хотя в данном конкретном случае это не приведет к агрегации нескольких чисел:
# Превращаем месяцы в колонки, годы оставляем в индексе, значения - пассажиры
flights_wide_df = flights_df.pivot_table(index='year',
columns='month',
values='passengers',
aggfunc='sum')
# aggfunc='sum' здесь для явности,
# т.к. для flights дубликатов (год, месяц) нет
display(flights_wide_df)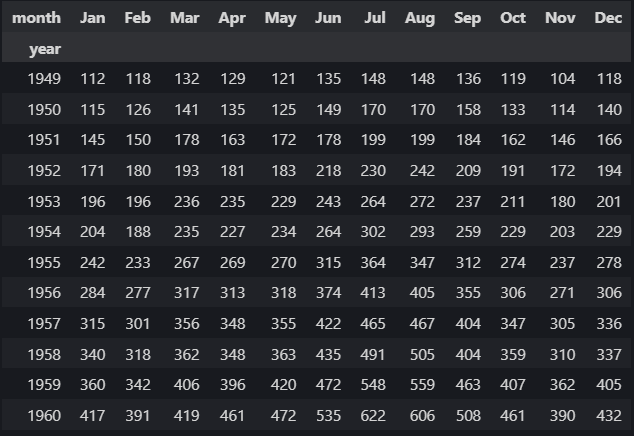
Взглянем на `flights_wide_df`:
Такая структура может быть значительно удобнее для визуального анализа динамики пассажиропотока по годам и месяцам, для быстрого сравнения показателей за разные месяцы одного года, или для использования в качестве входных данных для некоторых типов графиков (например, тепловых карт).
- Индекс: Столбец `year` стал индексом нашего нового датафрейма. Каждая метка строки теперь соответствует одному году.
- Столбцы: Уникальные значения из столбца `month` (Jan, Feb, Mar, ..., Dec) стали заголовками столбцов. Поскольку столбец `month` в исходном `flights_df` имеет категориальный тип с установленным порядком, `pivot_table` корректно расположила месяцы в календарном порядке.
- Значения: Ячейки таблицы теперь заполнены соответствующими значениями `passengers`. Например, в строке с индексом 1949 и в столбце Jan мы видим значение 112, что точно соответствует исходным данным..
Такая структура может быть значительно удобнее для визуального анализа динамики пассажиропотока по годам и месяцам, для быстрого сравнения показателей за разные месяцы одного года, или для использования в качестве входных данных для некоторых типов графиков (например, тепловых карт).
Совет
А что если у нас несколько колонок для `index` или `values`? `pivot_table` справится и с этим! Например, если бы в нашем датасете был столбец `quarter` (квартал), мы могли бы указать `index=['year', 'quarter']` для создания иерархического индекса, где каждая строка идентифицировалась бы уникальной комбинацией года и квартала. Подобным образом, если бы мы хотели агрегировать и представить в таблице несколько различных числовых показателей (скажем, `passengers` и `avg_ticket_price`), мы могли бы передать их списком в параметр `values`: `values=['passengers', 'avg_ticket_price']`. В таком случае Pandas автоматически создаст соответствующую структуру с многоуровневыми столбцами, если это необходимо для отображения всех комбинаций.
Теперь, когда мы научились "расширять" наши данные, превращая длинные списки в широкие таблицы, пора освоить обратную операцию – как "свернуть" широкие таблицы обратно в их первоначальный, длинный формат.
Из широкого формата в длинный
Мы только что мастерски "расширили" наш датафрейм `flights_df`, превратив его из длинного списка наблюдений в широкую таблицу `flights_wide_df`, где каждый месяц стал отдельным столбцом. Но что, если нам понадобится выполнить обратную операцию? Часто бывает так, что данные поступают в широком формате (например, из Excel-таблицы, где каждая колонка – это отдельная характеристика или временной период), а для дальнейшей обработки, визуализации или хранения в базе данных их удобнее представить в длинном формате.
Для таких задач "сворачивания" (unpivoting) столбцов обратно в строки в Pandas существует функция `melt`.
Функция melt()
Функция `pd.melt()` – это, по сути, антипод `pivot_table` (или, точнее, `pivot`). Если `pivot_table` берет значения из одной колонки и "разбрасывает" их по новым столбцам, то `melt` делает обратное: она собирает данные из нескольких столбцов и "складывает" их в две новые колонки.
Можно представить, что `melt` берет ваш широкий датафрейм как бы "плавит" указанные столбцы. Их заголовки (имена столбцов) "стекают" в одну новую колонку (обычно называемую `variable` по умолчанию), а значения из ячеек этих столбцов "стекают" в другую новую колонку (обычно `value` по умолчанию). При этом столбцы, которые вы указали как идентификаторы (`id_vars`), дублируются для каждой новой строки, образовавшейся в результате "плавления".
Основные параметры melt
Чтобы функция `melt` корректно "расплавила" вашу широкую таблицу, превратив ее в длинный формат, нужно указать ей несколько параметров. Вот основные из них:
Результатом "плавления" станут две новые колонки (по умолчанию):
И вы можете дать этим новым колонкам осмысленные имена с помощью параметров:
И, конечно, melt ожидает сам DataFrame для трансформации (параметр frame, который обычно передается первым).
Есть и другие, более тонкие настройки (вроде `col_level` для многоуровневых колонок или `ignore_index` для управления индексацией результата), но понимание `id_vars`, `var_name` и `value_name` (а также того, как работает `value_vars` по умолчанию) – самое важное
Давайте применим это к нашему `flights_wide_df`.
- id_vars (сокращение от identifier variables): Здесь вы перечисляете столбцы, которые должны остаться как есть и не подвергаться "плавлению". Эти столбцы будут играть роль идентификаторов, и их значения будут повторяться для каждой новой строки, образовавшейся из "расплавленных" данных.
- value_vars (сокращение от value variables): Этот параметр опционален. Если его указать, то "плавиться" будут только перечисленные здесь столбцы. Если же его опустить, `melt` "расплавит" все столбцы, которые не были указаны в id_vars. Это часто самый удобный способ.
Результатом "плавления" станут две новые колонки (по умолчанию):
- Одна колонка (по умолчанию `variable`) будет содержать имена тех столбцов, которые были "расплавлены".
- Другая колонка (по умолчанию `value`) будет содержать значения из ячеек этих "расплавленных" столбцов.
И вы можете дать этим новым колонкам осмысленные имена с помощью параметров:
- var_name: Задает имя для новой колонки, содержащей бывшие имена столбцов.
- value_name: Задает имя для новой колонки, содержащей бывшие значения из ячеек.
И, конечно, melt ожидает сам DataFrame для трансформации (параметр frame, который обычно передается первым).
Есть и другие, более тонкие настройки (вроде `col_level` для многоуровневых колонок или `ignore_index` для управления индексацией результата), но понимание `id_vars`, `var_name` и `value_name` (а также того, как работает `value_vars` по умолчанию) – самое важное
Давайте применим это к нашему `flights_wide_df`.
Применяем melt()
Теперь пришло время вернуть наш `flights_wide_df` к его первозданному, длинному виду. Но сначала нужно подготовить наш датафрейм: функция `melt` работает со столбцами, а в нашем `flights_wide_df` столбец `year` сейчас является индексом. Чтобы использовать `year` как `id_var` (идентификатор, который не нужно "плавить"), нам нужно сначала превратить индекс обратно в обычный столбец. Это легко сделать с помощью метода `.reset_index()`.
А после этого мы сможем применить `melt`, указав:
А после этого мы сможем применить `melt`, указав:
- `id_vars=['year']` (год – это наш идентификатор).
- Столбцы-месяцы (`value_vars`) можно не указывать явно, `melt` возьмет все остальные.
- `var_name='month'` (новая колонка с именами месяцев).
- `value_name='passengers'` (новая колонка со значениями пассажиров).
# Сначала сбросим индекс у flights_wide_df, чтобы 'year' стал обычной колонкой
flights_wide_reset_df = flights_wide_df.reset_index()
# Теперь "плавим" данные обратно в длинный формат
flights_long_again_df = flights_wide_reset_df.melt(id_vars=['year'],
var_name='month',
value_name='passengers')
print(flights_df.shape)
# (144, 3)
display(flights_long_again_df)
Сравним результат с тем, что у нас было в самом начале:
- `flights_long_again_df` теперь имеет три столбца: `year`, `month` и `passengers` – точно как наш исходный `flights_df`!
- Он также содержит 144 строки и 3 столбца, что совпадает с размерами `flights_df`.
- Если мы посмотрим на значения, то увидим, что данные успешно "собраны" обратно.
Теперь, когда мы овладели искусством как "расширения", так и "сворачивания" данных, пришло время обсудить, когда какой формат предпочтительнее.
Длинный vs. широкий
Какой же формат следует предпочесть в той или иной ситуации? Не существует универсального ответа, так как выбор оптимального формата данных напрямую зависит от того, какие операции вы планируете выполнять далее, какие инструменты будете использовать, и даже от того, насколько данные должны быть читаемы для человека. В этом разделе мы сосредоточимся на сравнительных преимуществах каждого формата для различных аналитических задач, чтобы помочь вам принимать более обоснованные решения.
Преимущества длинного формата
Длинный формат данных, где каждое наблюдение или измерение представлено отдельной строкой, предлагает ряд существенных преимуществ, особенно когда речь идет о программной обработке, сложных визуализациях и работе с определенными типами данных:
- Преимущества для продвинутой визуализации: Многие современные библиотеки для построения графиков, такие как `seaborn` или `plotly express`, оптимизированы для работы с данными в длинном формате. Это особенно актуально, когда требуется отобразить несколько переменных на одном графике, используя одну из них для группировки, определения цвета (hue), размера или формы маркеров. Длинный формат позволяет легко сопоставить категориальные переменные с измеряемыми значениями для таких сложных визуализаций.
- Удобство для статистического моделирования с повторяющимися измерениями: При анализе данных с повторяющимися измерениями (например, лонгитюдные исследования, где одни и те же субъекты измеряются многократно во времени) или иерархических данных, длинный формат часто является более естественным и удобным для спецификации моделей в статистических пакетах (например, для смешанных моделей).
- Оптимизация для операций группировки и агрегации: Выполнение операций `groupby` с последующей агрегацией значений часто более прямолинейно и эффективно на данных в длинном формате. Легко сгруппировать данные по одному или нескольким идентификационным столбцам и вычислить агрегаты для столбца значений.
- Гибкость при добавлении новых типов измерений или категорий: Если в процессе анализа или сбора данных появляется необходимость добавить новый тип измеряемой переменной или новую категорию в существующую переменную, в длинном формате это обычно сводится к добавлению новых строк с соответствующими идентификаторами и значениями, не требуя изменения структуры существующих столбцов.
- Эффективное хранение и обработка разреженных данных: В ситуациях, когда у вас много возможных комбинаций идентификаторов и измеряемых переменных, но значения существуют не для всех из них (разреженные данные), длинный формат позволяет хранить только фактически существующие наблюдения. Это может привести к более компактному хранению и более быстрой обработке по сравнению с широким форматом, который в таких случаях содержал бы много пустых ячеек (NaN).
- Соответствие принципам "Tidy Data" для предсказуемой работы: Длинный формат тесно связан с концепцией Tidy Data, где каждая переменная является столбцом, каждое наблюдение – строкой, и каждый тип наблюдаемой единицы формирует таблицу. Приверженность этим принципам делает структуру данных более предсказуемой и упрощает работу со стандартными инструментами анализа данных, ориентированными на такой подход.
В целом, длинный формат часто является предпочтительным для хранения, первичной обработки и подготовки данных к сложному анализу или визуализации.
Преимущества широкого формата
Несмотря на явные преимущества длинного формата для многих задач программной обработки, широкий формат, где каждая строка представляет уникальную сущность, а ее характеристики разнесены по столбцам, также обладает важными достоинствами и оказывается предпочтительным в ряде ключевых сценариев:
Таким образом, широкий формат часто является выбором по умолчанию, когда важна непосредственная читаемость данных человеком, требуется совместимость с определенными аналитическими инструментами, или когда данные естественным образом представляют собой набор фиксированных характеристик для каждого объекта.
- Интуитивная понятность и наглядность для человека: Для непосредственного визуального анализа и быстрого сравнения всех характеристик одного конкретного объекта или субъекта широкий формат часто является более удобным и интуитивно понятным. Вся информация об одном объекте собрана в одной строке, что облегчает ее восприятие человеком без необходимости "прокручивать" множество строк, как это могло бы быть в длинном формате.
- Требования многих статистических пакетов и алгоритмов машинного обучения: Значительное количество классических статистических процедур и большинство алгоритмов машинного обучения (например, в библиотеке `scikit-learn`) ожидают на вход данные в виде матрицы "объекты-признаки". В такой структуре каждая строка представляет собой отдельный объект (наблюдение, экземпляр), а каждый столбец – отдельный признак (фичу, переменную). Широкий формат данных идеально соответствует этому требованию.
- Удобство для создания итоговых отчетов и сводных таблиц: Если конечная цель – подготовить сводную таблицу для отчета, презентации или для пользователя, не являющегося специалистом по данным, широкий формат часто оказывается более предпочтительным. Таблицы, где, например, по строкам идут продукты, а по столбцам – их месячные продажи или другие характеристики, легко читаются и интерпретируются.
- Простота выполнения вычислений между различными переменными для одной сущности: Если вам необходимо выполнить вычисления, включающие несколько различных переменных для одной и той же сущности (например, рассчитать разницу между двумя показателями, или создать новую производную характеристику на основе нескольких существующих столбцов), широкий формат может сделать эти операции более прямыми, так как все необходимые данные для одной сущности находятся в одной строке.
- Компактность представления при небольшом и фиксированном наборе переменных: Если количество характеристик или временных точек, которые вы анализируете для каждой сущности, невелико и относительно постоянно, широкий формат может обеспечить более компактное и менее избыточное визуальное представление по сравнению с длинным форматом, где идентификаторы могут многократно повторяться.
- Совместимость с некоторыми инструментами бизнес-аналитики (BI) и электронными таблицами: Некоторые BI-инструменты и, конечно же, программы для работы с электронными таблицами (как Microsoft Excel) исторически лучше приспособлены или более интуитивно работают с данными, представленными в широком формате.
Таким образом, широкий формат часто является выбором по умолчанию, когда важна непосредственная читаемость данных человеком, требуется совместимость с определенными аналитическими инструментами, или когда данные естественным образом представляют собой набор фиксированных характеристик для каждого объекта.
Заключение
Задайте себе ключевой вопрос: "Что представляет собой одна строка в моей таблице на данном этапе анализа?"
- Если ответ: "Одна строка – это одно конкретное измерение, одно событие, или одно значение переменной из многих возможных для одного и того же объекта (например, 'температура в полдень для города X', 'покупка товара Y клиентом Z')", то, скорее всего, вам нужен или вы уже имеете дело с длинным форматом.
- Если ответ: "Одна строка – это один уникальный объект, один субъект, или одна сущность со всеми ее измеренными атрибутами или значениями переменных, представленными в разных колонках (например, 'город X' со столбцами 'Температура_Утро', 'Температура_Полдень', 'Температура_Вечер')", то это указывает на широкий формат.
Это простое правило помогает сфокусироваться на семантике строк, что часто является определяющим фактором.
Лайфхак
Не стоит рассматривать выбор формата как однократное и окончательное решение. В реальном рабочем процессе анализа данных часто приходится многократно преобразовывать данные. Например, вы можете начать с длинного формата для очистки и некоторых агрегаций, затем преобразовать данные в широкий формат для расчета новых признаков или для передачи в модель, а затем, возможно, снова вернуться к длинному формату (или его части) для создания специфических визуализаций. Pandas и его функции, такие как `pivot_table`, `melt`, `stack`, `unstack`, созданы именно для такой гибкой работы. Главное – четко понимать, какой формат нужен для каждого шага, и уметь его получить.
Владение техниками трансформации данных и понимание контекстных преимуществ каждого формата позволяет вам не быть заложником исходной структуры данных, а активно формировать ее так, как это наиболее эффективно для достижения ваших аналитических целей.