
Андрей Карпаты, легенда мира AI и один из создателей OpenAI и Tesla Autopilot, снова встряхнул сообщество. Он выложил nanochat — проект, который можно назвать одним из самых полезных репозиториев за последнее время.
В чем суть? Это полный конвейер для создания LLM-клона ChatGPT с нуля. Всего 8000 строк чистого, минималистичного кода, который демистифицирует весь процесс: от обучения токенизатора и предобучения модели до файнтюнинга и даже обучения с подкреплением (RL).
Карпаты делает "спидран": сборку языковой модели, которую можно реализовать за $100 и примерно 4 часа работы на облачном сервере с 8xH100 GPU.
Мы разберем проект nanochat по винтикам и поймем, что происходит на каждом этапе.
«Спидран» за $100
Карпаты арендует мощный сервер (например, в Lambda GPU Cloud) с восемью видеокартами H100. Такая машина стоит примерно $24 в час. Бюджет ограничен сотней долларов. Это значит, что есть чуть больше 4 часов, чтобы из хаоса интернет-текстов родилась маленькая языковая модель.
[!NOTE] Философия nanochat Весь репозиторий пронизан идеей минимализма. Карпаты сознательно избегает громоздких фреймворков и лишних зависимостей. Его цель — создать понятную, связную и легко модифицируемую кодовую базу, которую можно изучать, форкать и использовать как основу для собственных исследований.
В репозитории есть скрипт speedrun.sh, который автоматизирует весь процесс от А до Я. Но мы же здесь не для того, чтобы просто нажать кнопку, верно? Мы пройдем по этому скрипту шаг за шагом, комментируя каждую деталь.
Поехали: Пошаговый разбор
Итак, мы залогинились на наш свежеарендованный сервер. Время пошло.
Шаг 1: Подготовка окружения — uv и Rust
Первым делом — клонируем репозиторий и настраиваем рабочее окружение.
git clone https://github.com/karpathy/nanochat.git
cd nanochat
Дальше начинается интересное. Карпаты использует не pip или conda, а uv.
# Устанавливаем uv, если его еще нет
command -v uv &> /dev/null || curl -LsSf https://astral.sh/uv/install.sh | sh
# Создаем локальное виртуальное окружение .venv
[ -d ".venv" ] || uv venv
# Устанавливаем зависимости
uv sync
# Активируем окружение
source .venv/bin/activate
[!INFO] Что за
uv?uv— новый и чертовски быстрый менеджер пакетов и виртуальных окружений для Python, написанный на Rust. Он позиционируется как заменаpipиvenv, и его главное преимущество — скорость.
Следующий этап может удивить: нам понадобится Rust.
# Устанавливаем Rust и его пакетный менеджер Cargo
curl --proto '=https' --tlsv1.2 -sSf https://sh.rustup.rs | sh -s -- -y
source "$HOME/.cargo/env"
# Собираем кастомный токенизатор на Rust
uv run maturin develop --release --manifest-path rustbpe/Cargo.toml
Зачем здесь Rust? Ответ прост: для обучения токенизатора. Карпаты отмечает, что его предыдущая реализация на чистом Python (minbpe) оказалась слишком медленной, а готовые решения от Hugging Face — излишне громоздкими и запутанными. В мире, где скорость — наше всё, кастомный токенизатор на Rust — это оправданный шаг. Утилита maturin как раз и служит мостом, позволяя легко собирать Rust-код в Python-модуль.
На этом подготовка завершена. Наше окружение готово к созданию мозга нашей будущей модели.
Шаг 2: Обучение токенизатора — Создаем словарь для нашего LLM
Прежде чем модель сможет "читать" текст, ей нужен словарь. Токенизатор — это и есть этот словарь. Он разбивает текст на осмысленные кусочки (токены) и переводит их в числа, понятные машине.
Сначала — данные
Чтобы обучить токенизатор, а затем и саму модель, нам нужны данные. Много данных. Карпаты использует датасет FineWeb-EDU — это гигантская коллекция отфильтрованных веб-страниц образовательного характера.
Чтобы не тащить тяжеловесную библиотеку huggingface/datasets, Карпаты сделал простую вещь: он перепаковал датасет в удобные для стриминга "шарды" и выложил их на Hugging Face Hub. Каждый шард — это parquet-файл, сжатый gzip, размером около 100 МБ.
Для модели с глубиной 20 (d20) нам понадобится 240 таких шардов. Это примерно 24 ГБ данных. На облачном сервере они скачиваются довольно быстро.
# Запускаем скачивание 240 шардов данных.
# По умолчанию они попадут в ~/.cache/nanochat
python -m nanochat.dataset -n 240
[!TIP] В скрипте
speedrun.shКарпаты хитро запускает скачивание 240 шардов в фоновом режиме, в то время как обучение токенизатора начинается на первых 8 уже скачанных шардах. Это отличный пример оптимизации времени!
Запускаем обучение
Как только первые данные на месте, мы можем обучить наш словарь. Мы будем создавать словарь размером 65,536 токенов (2**16). Обучение пройдет на первых 2 миллиардах символов и займет всего около минуты.
python -m scripts.tok_train --max_chars=2000000000
python -m scripts.tok_eval
После обучения скрипт tok_eval выдает интересный отчет. Главный показатель — коэффициент сжатия (compression ratio). Он показывает, сколько в среднем символов исходного текста "упаковывается" в один токен. У нас он будет в районе 4.8.
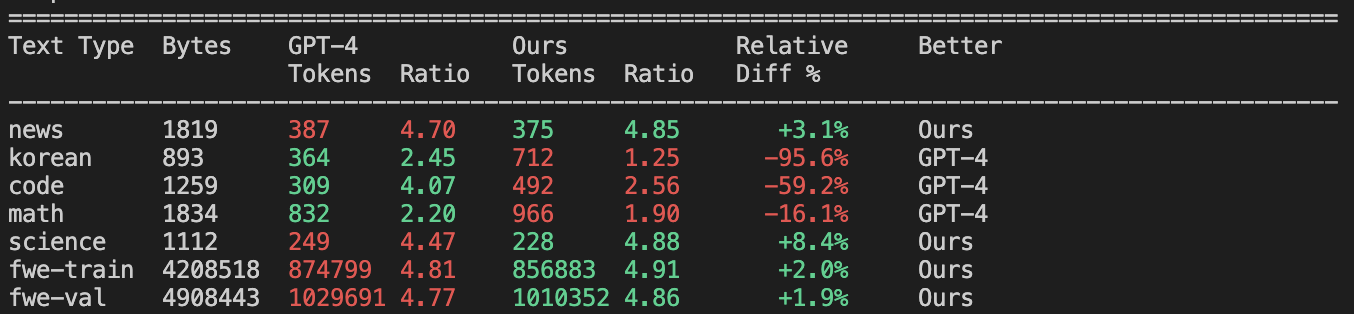
Карпаты также сравнивает этот свежеобученный токенизатор с эталонными от OpenAI: GPT-2 и GPT-4.
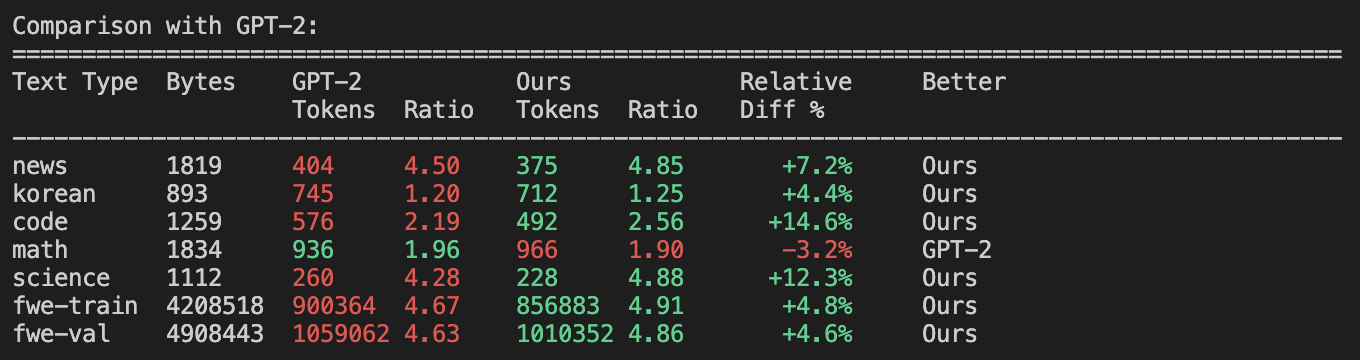
- По сравнению с GPT-2 (50,257 токенов): токенизатор сжимает текст значительно лучше почти по всем категориям, немного уступая лишь в математических формулах.
- По сравнению с GPT-4 (100,277 токенов): Здесь он ожидаемо проигрывает, особенно на многоязычных текстах, коде и математике. У GPT-4 просто больше "словарный запас". Но что интересно, на самом датасете FineWeb наш токенизатор даже немного обгоняет GPT-4, потому что он идеально "заточен" под распределение данных, на которых обучался.
Наш собственный, кастомный и эффективный словарь готов. Модель почти готова начать учиться.
Шаг 3: Pretraining (Предобучение) — Рождение интеллекта
Это самый важный и вычислительно дорогой этап. Здесь LLM будет впитывать в себя знания из гигабайтов текста. Процесс прост по своей сути: модель учится предсказывать следующее слово (точнее, токен) в последовательности. Именно так она изучает грамматику, факты, логику и обретает "знания о мире".
Последние приготовления
Перед запуском нам нужен еще один компонент — "eval bundle". Это набор данных для оценки метрики CORE, которая измеряет "общую эрудицию" модели на 22 различных задачах (ответов на вопросы, логических задач и т.д.).
# Скачиваем и распаковываем eval_bundle
curl -L -o eval_bundle.zip https://karpathy-public.s3.us-west-2.amazonaws.com/eval_bundle.zip
unzip -q eval_bundle.zip
rm eval_bundle.zip
mv eval_bundle "$HOME/.cache/nanochat"
Для визуализации процесса обучения можно использовать wandb (Weights & Biases). Это позволит в реальном времени следить за графиками потерь и метрик.
# Если еще не сделали, залогиньтесь в wandb
wandb login
Запускаем!
Теперь все готово для запуска самой тяжелой артиллерии. Мы запускаем скрипт base_train.py на всех 8 GPU. Мы будем обучать модель-трансформер с 20 слоями (depth=20).
torchrun --standalone --nproc_per_node=8 -m scripts.base_train -- --depth=20
[!NOTE] Если вы настроили
wandb, добавьте флаг--run=speedrun(или любое другое имя), чтобы логи отправлялись в ваш проект.
После запуска в консоли появится много информации:
Vocab size: 65,536
num_layers: 20
model_dim: 1280
...
Number of parameters: 560,988,160
...
Total number of training tokens: 11,219,763,200
Tokens : Params ratio: 20.00
Total training FLOPs estimate: 3.917670e+19
...
step 00001/21400 (0.00%) | loss: 10.808654 | ... | tok/sec: 807,569 | mfu: 35.64 | ...
step 00002/21400 (0.01%) | loss: 10.179083 | ... | tok/sec: 1,110,094 | mfu: 48.99 | ...
...
Что значат все эти цифры?
- Parameters: Наша модель имеет ~560 миллионов параметров.
- Tokens:Params ratio: Чтобы соответствовать закону масштабирования Chinchilla, модели такого размера нужно "скормить" примерно в 20 раз больше токенов, чем у нее параметров. Это около 11.2 миллиардов токенов.
- FLOPs: Весь процесс обучения потребует ~4e19 (40 экзафлопс) вычислительных операций. Это и есть "мощность" будущей модели.
- Iterations: Исходя из размера батча и общего количества токенов, понадобится ~21,400 шагов оптимизации.
- tok/sec & mfu:
tok/sec— это скорость обработки токенов в секунду.mfu(Model FLOPs Utilization) — это процент утилизации теоретической вычислительной мощности GPU. Значение в районе 50% — это очень хороший показатель.
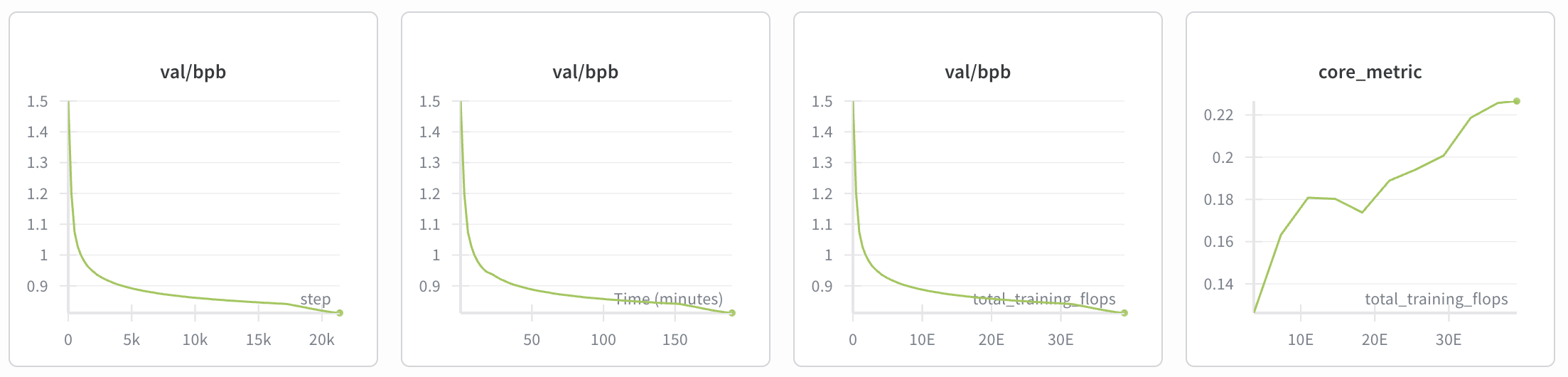
Теперь остается только ждать. Процесс займет около 3 часов. В это время 8 видеокарт H100 будут трудиться на полную, а мы можем наблюдать за магией в wandb. График loss (ошибки) должен плавно снижаться, а метрика CORE — расти. Это значит, что модель становится умнее.
Первые результаты
По завершении предобучения наша модель — это, по сути, очень навороченный автокомплит. Она знает факты, но еще не умеет общаться в формате диалога. Мы можем проверить ее базовые знания:
# Запускаем скрипты для оценки потерь и метрик
torchrun --standalone --nproc_per_node=8 -m scripts.base_loss
torchrun --standalone --nproc_per_node=8 -m scripts.base_eval
Модель достигает метрики CORE около 0.22. Для сравнения, это чуть лучше, чем GPT-2 Large (0.21), но немного хуже, чем GPT-2 XL (0.26).
Проверим на простых запросах:
The capital of France is->Paris.(Знает!)The chemical symbol of gold is->Au.(Знает!)The planets of the solar system are:->Mercury, Venus, Earth, Mars, Jupiter, Saturn, Uranus, Neptune,(Знает!)If 5*x + 3 = 13, then x is->a positive integer.(Математику пока не осилила, но поняла, что речь о числах).
Неплохо для модели, на обучение которой ушло $72. Но это еще не чат-бот. Чтобы научить ее диалогу, мы переходим к следующим этапам.
Шаг 4: Midtraining — Учим модель правилам хорошего тона
Модель уже выучила слова и факты, но пока не умеет вести диалог. Этап midtraining (промежуточное дообучение) — это как отправить её в школу, где её научат общаться, решать задачки и пользоваться инструментами.
Этот этап гораздо быстрее предобучения и занимает всего около 8 минут. Здесь мы дообучаем нашу базовую модель на новом типе данных — на диалогах. Алгоритмически это то же самое обучение, но цели у него другие.
Чему мы учим модель на этом этапе?
- Формату диалога: Модель знакомится со специальными токенами, такими как
<|user_start|>,<|assistant_start|>и<|assistant_end|>. Она учится понимать структуру "вопрос-ответ". - Решать тесты (Multiple Choice): Маленькие модели, в отличие от гигантов вроде GPT-4, не всегда понимают сам формат тестов с вариантами A, B, C, D. На этом этапе мы "подмешиваем" в обучающие данные 100 тысяч вопросов из датасета MMLU. Модель не столько учит новые факты, сколько учится алгоритму: "увидел вопрос и варианты -> выбери правильную букву". Это критически важно, так как многие бенчмарки (MMLU, ARC) построены именно на таких тестах.
- Использовать инструменты: Мы учим модель пользоваться калькулятором. Это реализуется через специальные токены
<|python_start|>и<|python_end|>. Модель учится "заворачивать" математические выражения в эти теги, чтобы внешний интерпретатор мог их вычислить. Это необходимо для решения математических задач из датасета GSM8K.
Запускаем Midtraining
Процесс запускается одной командой:
torchrun --standalone --nproc_per_node=8 -m scripts.mid_train
После завершения этого короткого, но важного этапа, модель превращается из простого автокомплита в полноценного чат-ассистента. Теперь мы можем оценить ее производительность на специализированных "чатовых" бенчмарках.
torchrun --standalone --nproc_per_node=8 -m scripts.chat_eval -- -i mid
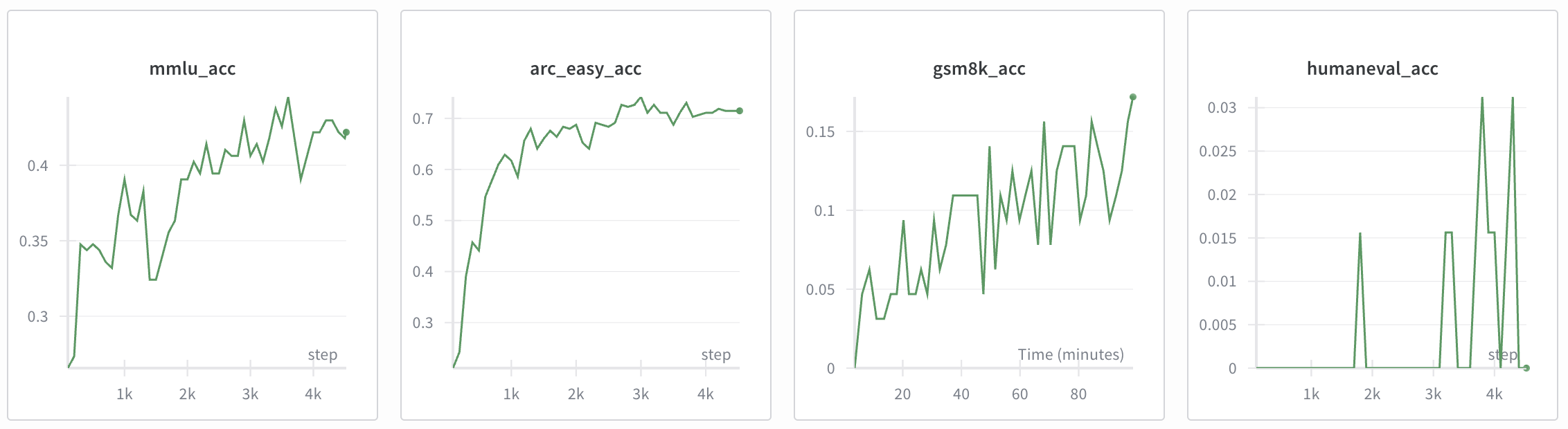
Флаг -i mid указывает скрипту, что нужно оценивать модель после этапа midtraining. Результаты будут примерно такими:
- MMLU: 0.3111 (на 31% вопросов отвечает верно, что лучше случайного угадывания 25%)
- GSM8K: 0.0250 (решает 2.5% простых математических задач)
- HumanEval: 0.0671 (решает 6.7% задач на программирование)
Показатели пока скромные, но мы видим, что модель уже приобрела новые навыки. Чтобы "затянуть гайки" и еще немного улучшить ее производительность, переходим к следующему этапу.
Шаг 5: Supervised Finetuning (SFT) — Финальная полировка
SFT (контролируемое дообучение) — это еще один короткий раунд файнтюнинга на диалогах. Он длится около 7 минут и служит для финальной "полировки" модели.
В чем отличие от Midtraining?
- Качество данных: В идеале, на этапе SFT используются только самые качественные, "красивые" примеры диалогов. Здесь же обычно происходит обучение безопасности (например, как правильно отказывать в выполнении вредоносных запросов). Наша модель пока не настолько умна, чтобы представлять опасность, так что мы этот аспект опускаем.
- Формат данных: Главное техническое отличие — на этом этапе данные подаются в модель точно в таком же виде, как и во время реального использования (инференса). На этапах pretraining и midtraining для эффективности длинные тексты и диалоги "склеивались" в большие батчи. SFT устраняет это небольшое несоответствие, что дает маленький, но заметный прирост в качестве.
Запускаем SFT и последующую оценку:
torchrun --standalone --nproc_per_node=8 -m scripts.chat_sft
torchrun --standalone --nproc_per_node=8 -m scripts.chat_eval -- -i sft
Результаты снова немного подрастают:
- MMLU: 0.3151 (было 0.3111)
- GSM8K: 0.0455 (было 0.0250)
- HumanEval: 0.0854 (было 0.0671)
Время поговорить!
Наконец-то! Наша модель полностью готова к диалогу. Мы можем пообщаться с ней прямо в терминале или через удобный веб-интерфейс.
# Вариант 1: Чат в командной строке
python -m scripts.chat_cli
# Вариант 2: Веб-интерфейс в стиле ChatGPT
python -m scripts.chat_web
При запуске chat_web скрипт поднимет веб-сервер. Чтобы получить доступ, нужно в браузере ввести публичный IP-адрес вашего сервера и порт 8000, например: http://209.20.xxx.xxx:8000/.
И вот он, результат трудов:
Конечно, такая модель не выиграет конкурс поэзии или олимпиаду по физике. Но сам факт, что можно с нуля создать вполне сносного собеседника, потратив меньше $100 и 4 часов, впечатляет.
Шаг 6 Reinforcement Learning (RL) — Тренировка на результат
Последний этап, который в speedrun.sh по умолчанию закомментирован, — это обучение с подкреплением (Reinforcement Learning). В больших моделях RLHF (RL from Human Feedback) используется для тонкой настройки и согласования ответов модели с человеческими предпочтениями.
В нашем масштабе это не так критично. Но есть одна область, где RL может дать заметный прирост, — это задачи с четким и объективным критерием правильности. Например, математические задачи из GSM8K. Ответ либо правильный, либо нет.
Скрипт chat_rl запускает простой цикл RL:
- Модель генерирует несколько вариантов решения для задачи из GSM8K.
- Каждое решение проверяется: если ответ верный, решение получает "награду" (reward) = 1, иначе 0.
- Модель дообучается на тех вариантах, которые получили высокую награду.
Этот процесс "натаскивает" модель на генерацию правильных ответов.
# Запускаем RL-обучение
torchrun --standalone --nproc_per_node=8 -m scripts.chat_rl
# Оцениваем результат только на GSM8K
torchrun --standalone --nproc_per_node=8 -m scripts.chat_eval -- -i rl -a GSM8K
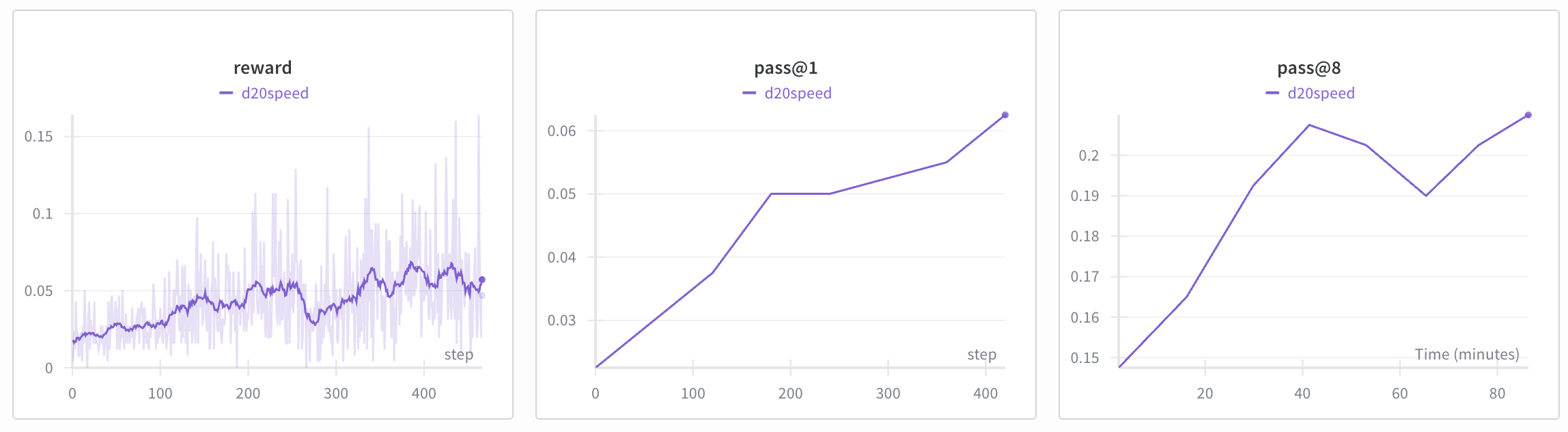
Процесс RL довольно медленный, так как модель получает очень мало "битов" информации (только 1 или 0 на целое решение). По умолчанию он занимает около 1.5 часов. Но результат заметен: точность на GSM8K может вырасти еще, например, с 4.5% до 7.5%.
Карпаты отмечает, что этот этап пока не очень хорошо настроен и создает модель, "заточенную" под математику, а не универсального чат-бота. Поэтому он и является опциональным.
Что мы получили за свои $100?
По завершении всех этапов в директории проекта появляется файл report.md. Это своего рода "табель успеваемости" спидрана, содержащий всю ключевую информацию о запуске и итоговые метрики.
Отчет начинается с раздела, который показывает, насколько минималистичен сам проект:
- Characters: 333,989
- Lines: 8,304
- Files: 44
- Dependencies (uv.lock lines): 2,004
Всего 8 тысяч строк кода и минимум зависимостей для создания целого ChatGPT-клона!
Но самое интересное — это итоговая таблица с метриками на каждом этапе.
| Metric | BASE | MID | SFT | RL |
|---|---|---|---|---|
| CORE | 0.2219 | - | - | - |
| ARC-Challenge | - | 0.2875 | 0.2807 | - |
| ARC-Easy | - | 0.3561 | 0.3876 | - |
| GSM8K | - | 0.0250 | 0.0455 | 0.0758 |
| HumanEval | - | 0.0671 | 0.0854 | - |
| MMLU | - | 0.3111 | 0.3151 | - |
| ChatCORE | - | 0.0730 | 0.0884 | - |
Что здесь видно:
- BASE: предобученная модель имеет CORE-метрику 0.22, подтверждая уровень чуть выше GPT-2 Large.
- MID -> SFT: Мы видим четкий прогресс. После
midtrainingмодель уже показывает базовые способности в решении задач (MMLU, GSM8K, HumanEval). ПослеSFTэти показатели еще немного подрастают. - RL: Опциональный этап RL дает самый большой прирост в конкретной задаче, на которой он обучался — GSM8K (с 4.5% до 7.5%).
И главный итог: Total wall clock time: 3h51m
С учетом стоимости сервера $24/час, общие затраты составили (3 + 51/60) * 24 = $92.4.
Что дальше?
Самое прекрасное в nanochat то, что Карпаты дает в руки не просто инструмент, а целую песочницу для экспериментов. Вы можете менять все: токенизатор, данные для обучения, гиперпараметры.
Самый простой способ получить более мощную модель — увеличить ее глубину. Это делается с помощью одного-единственного параметра --depth на этапе base_train. Код устроен так, что все остальные параметры (ширина слоев, learning rate и т.д.) подстроятся автоматически.
Например, чтобы получить модель уровня GPT-2 (CORE-метрика ~0.25), можно попробовать depth=26. Но для этого потребуется больше данных, и, что важнее, придется уменьшить размер батча на каждом устройстве, чтобы не словить ошибку нехватки видеопамяти (OOM).
Пример для обучения модели d26 (~12 часов, ~$300):
# Уменьшаем device_batch_size с 32 до 16
torchrun --standalone --nproc_per_node=8 -m scripts.base_train -- --depth=26 --device_batch_size=16
Код автоматически поймет, что для достижения целевого общего размера батча ему теперь нужно делать 2 шага градиентной аккумуляции вместо одного.
Пример для обучения модели d30:
# Уменьшаем device_batch_size еще сильнее
torchrun --standalone --nproc_per_node=8 -m scripts.base_train -- --depth=30 --device_batch_size=8
Не бойтесь читать и изменять код. Он написан предельно чисто и хорошо прокомментирован.
Понравился материал?
Ваша поддержка — это энергия для новых статей и проектов. Спасибо, что читаете!
Заключение
В итоге, nanochat — это мощнейший образовательный инструмент, который снимает завесу тайны с процесса создания больших языковых моделей. Он демократизирует доступ к технологиям, которые еще вчера казались уделом мегакорпораций.
Проект Карпаты доказывает, что для серьезных экспериментов и получения работающих моделей не всегда нужны многомиллионные бюджеты. Он дает в руки сообществу "сильный базовый" стек (strong baseline), который можно использовать как отправную точку для собственных исследований, обучения и создания новых продуктов.
Экспериментируйте!