
В Data Science одним из важнейших этапов перед построением любой модели является подготовка данных. Значительная часть информации, с которой мы сталкиваемся в реальной жизни, представлена в виде категориальныхзначений. Однако большинство алгоритмов машинного обучения умеют работать только с числами. Именно поэтому возникает необходимость в кодировании категориальных данных — процессе преобразования категорий в числовой формат.
Давайте разберемся, какие бывают категориальные данные и какие существуют методы их кодирования.
Что такое категориальные данные?
Раз уж вся эта статья про категориальные данные, то давайте подробнее обсудим, что это такое. Если совсем кратно, то это данные с ограниченным числом уникальных значений.
Категориальные данные могут быть двух видов: порядковыми и номинальными.
Номинальные категории. Такие значения не могут быть проранжированы, и нет логической возможности их порядкового сравнения между собой. Примеры:
- Города: Москва, Санкт-Петербург, Казань.
- Профессии: врач, учитель, инженер.
- Виды товаров: яблоки, бананы, апельсины.
Порядковые категории. Такие значения могут быть упорядочены, и их можно сравниваться друг с другом. Примеры:
Понимание, к какому типу относятся ваши данные, — первый шаг к выбору правильного метода кодирования.
- Уровень образования: начальное, среднее, высшее.
- Размер одежды: S, M, L.
- Оценка удовлетворенности: плохо, удовлетворительно, хорошо, отлично.
Понимание, к какому типу относятся ваши данные, — первый шаг к выбору правильного метода кодирования.
Label Encoding и Ordinal Encoding
Эти способы кодирования используется, когда категории являются порядковыми. Каждое уникальное значение преобразуется в целочисленное, таким образом, все значения просто преобразовываются в числовой ряд по возрастанию.
Для примеров мы будем использовать библиотеку category_encoders:
import category_encoders as ce
import pandas as pd
df = pd.DataFrame({'size': ['L', 'M', 'S', 'L', 'M', 'S']})
encoder = ce.OrdinalEncoder(
cols=['size'],
mapping=[{'col': 'size', 'mapping': {'S': 0, 'M': 1, 'L': 2}}]
)
df['encoded'] = encoder.fit_transform(df)
df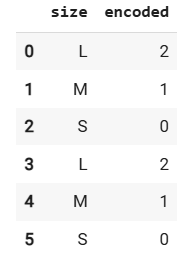
Если Ordinal Encoding используется для кодирования признаков в данных, то Label Encoding применяется для кодирования целевой переменной (хоть и работает аналогично).
Важно: не используйте эти методы для номинальных данных (например, цветов), иначе модель подумает, что между категориями есть порядок, которого на самом деле нет.
One-Hot Encoding
Этот метод используется для кодирования номинальных категорий. Каждая уникальная категория преобразуется в отдельный бинарный столбец (или массив). Для каждого объекта в новом столбце ставится 1, если он принадлежит к соответствующей категории, и 0 во всех остальных столбцах. Количество новых столбцов равно количеству уникальных значений в исходном категориальном признаке. Полученные бинарные признаки часто называют фиктивными (dummy variables).
Один из способ сделать это в Python представлен ниже:
df = pd.DataFrame({'city': ['Москва', 'Казань', 'Санкт-Петербург', 'Москва']})
encoder = ce.OneHotEncoder(cols='city', use_cat_names=True)
df_encoded = encoder.fit_transform(df)
df_encoded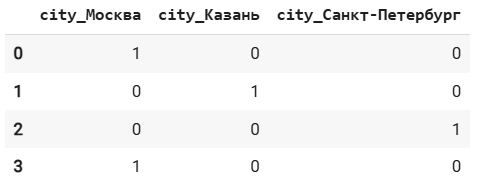
Такой способ не создаёт ложного порядка в номинальных категориях, но если категорий много (например, 50 городов), получится 50 новых столбцов, что увеличит размерность данных.
Также этот способ порождает мультиколлинеарность — когда один столбец предсказуем из других. Решение простое – удаляем один из столбцов в рамках каждого кодируемого признака.
Также этот способ порождает мультиколлинеарность — когда один столбец предсказуем из других. Решение простое – удаляем один из столбцов в рамках каждого кодируемого признака.
Effect Encoding (Sum Encoding)
Этот метод похож на OHE, но вместо того чтобы все значения были 0 или 1, одна из категорий становится "базовой" и кодируется как -1. Это полезно в линейных моделях, чтобы коэффициенты лучше интерпретировались.
Наглядно разницу видно в примере:
df = pd.DataFrame({'city': ['Москва', 'Казань', 'Санкт-Петербург', 'Москва']})
encoder = ce.SumEncoder(cols='city')
df_encoded = encoder.fit_transform(df)
df_encoded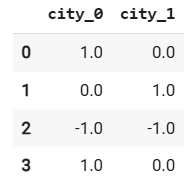
Здесь "Казань" — базовая категория, поэтому её значения — -1. Это помогает моделям избежать избыточности, как в OHE.
Hash Encoding
Подобно One-Hot Encoding, этот метод преобразует каждую категорию в несколько новых столбцов с бинарными значениями (0 или 1). Однако ключевое отличие заключается в том, что при Hash Encoding вы можете самостоятельно определить количество этих новых столбцов (`n_components`). Это особенно актуально, когда категорий очень много, и мы хотим уменьшить размерность признакового пространства. Однако этот метод необратим – после преобразования восстановить исходные данные не получится, т.к. разные категории могут быть преобразованы одинаково, если мы используем размерность меньшую, чем общее количество значений в признаке.
data = pd.DataFrame({'product': ['ноутбук', 'смартфон', 'планшет', 'наушники', 'ноутбук']})
encoder = ce.HashingEncoder(cols='product', n_components=3)
df_encoded = encoder.fit_transform(data)
df_encoded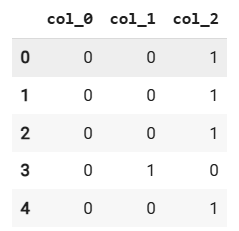
Binary Encoding
Binary Encoding представляет собой комбинацию Hash Encoding и One-Hot Encoding, позволяя решить проблему как потенциальной потери информации при хэшировании, так и чрезмерного увеличения размерности при однократном кодировании.
Суть метода заключается в следующем: сначала категории преобразуются в порядковые числа, затем эти числа переводятся в их двоичное представление. Каждый бит двоичного представления становится новым признаком.
Суть метода заключается в следующем: сначала категории преобразуются в порядковые числа, затем эти числа переводятся в их двоичное представление. Каждый бит двоичного представления становится новым признаком.
df = pd.DataFrame({'brand': ['Lada', 'Kia', 'BMW', 'Lada', 'Kia']})
encoder = ce.BinaryEncoder(cols=['brand'])
df_encoded = encoder.fit_transform(df)
df_encoded
Мы видим, что новых столбцов меньше, чем значений, но при этом все значения преобразованных признаков отличаются друг от друга, то есть мы не теряем информацию. Такой способ очень полезен, когда категориальных признаков и их значений очень много.
Base-N Encoding
Base-N Encoding – это обобщение представления категорий в произвольной системе счисления. Если выбрать базу 2, то результат аналогичен One-Hot Encoding. При выборе другой базы (например, 5) каждая категория будет записываться не бинарным, а пятиричным кодом, что позволяет сократить число новых признаков.
Пример с базой 5:
Пример с базой 5:
df = pd.DataFrame({'month': ['январь', 'февраль', 'март', 'апрель', 'май', 'июнь', 'июль']})
encoder = ce.BaseNEncoder(cols=['month'], base=5)
df_encoded = encoder.fit_transform(df)
df_encoded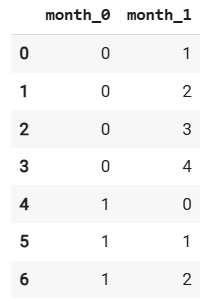
Если базу не указывать, то по умолчанию она будет равна двум, и мы получим результат, аналогичный one-hot-кодированию.
Target Encoding
Target Encoding — это метод преобразования категориального признака на основе среднего значения целевой переменной для каждой категории. Это своего рода байесовский метод, использующий информацию о зависимой переменной для кодирования категорий.
Для каждой категории вычисляется среднее значение целевой переменной, и это среднее значение используется для замены исходной категории.
Для каждой категории вычисляется среднее значение целевой переменной, и это среднее значение используется для замены исходной категории.
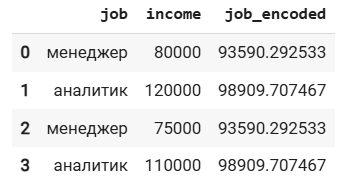
df = pd.DataFrame({
'job': ['менеджер', 'аналитик', 'менеджер', 'аналитик'],
'income': [80000, 120000, 75000, 110000]
})
encoder = ce.TargetEncoder(cols='job')
df['job_encoded'] = encoder.fit_transform(df['job'], df['income'])
dfВажно: следует использовать этот метод с осторожностью, так как он может привести к переобучению модели из-за использования информации о целевой переменной при создании признаков (что по сути является утечкой данных). Рекомендуется применять техники регуляризации и кросс-валидации.
Заключение: как выбрать метод?
Как мы увидели, существует множество способов кодирования категориальных данных, и каждый из них имеет свои особенности, преимущества и недостатки. Выбор конкретного метода зависит от типа категориальных данных (номинальные или порядковые), количества уникальных категорий, особенностей используемой модели машинного обучения и целей вашего анализа.
- Порядковые данные: используем Ordinal Encoding.
- Номинальные данные с небольшим числом категорий: One-Hot Encoding.
- Много категорий: Binary, Hash или Target Encoding.
Всегда проверяйте несколько методов и выбирайте тот, который повышает качество вашей модели